








Programs can be unnecessarily complex. Rafael Jay examines a technique for doing better.
You have the requirements for a new feature. Your customers need it done on time. You start designing. You know it will touch a few areas of your codebase so you start by looking at those. It's hard to get a clear picture of how they work so you draw a few class and sequence diagrams. Eventually you think you understand, but there's a lot of detail and you have to keep referring back to your diagrams. Deadlines are looming so you start coding. A week in you realise that strange dependency which didn't seem important actually disguised a key connection to another part of the system. Your design doesn't quite work. You don't have time to go back to the drawing board so you hack something together. You feel bad but you have to meet your customer commitments.
Next time round you're wiser. You know that code is tricky so you ask your manager for a couple of extra weeks to refactor it first. But refactor it into what? It's hard to draw a boundary around the area you're looking at and other parts of the code. And it's not entirely clear what you should refactor it into anyway - where should each class go? You do your best to apply some patterns and good software engineering techniques, but you keep having to back off because of unexpected dependencies. Two weeks later you've cleaned up a few localized issues, but you're not convinced you made that much difference overall. And behind that you have a nagging suspicion that this wasn't even the worst part of the codebase. Maybe you should have spent the time refactoring something else.
If these experiences sound familiar, your code is probably too complex. But what is complexity? We know what too much feels like: you discover one more thing to think about and suddenly your head explodes. You can't keep a clear picture of how it all fits together any more. This kind of anecdotal measure - how much it makes your head hurt - is perfectly valid and there's no reason why you shouldn't use it as an input into your refactoring efforts. But it's hard to compare different developers' sore heads to identify the most problematic areas, and it doesn't offer much insight into why their heads are hurting. We could do with something a bit more scientific.
Kettles
One explanation of complexity I have often found useful comes from Christopher Alexander's 1964 book Notes on the Synthesis of Form [Notes]. This book is concerned with the design of complex artefacts, which I'm sure most people would agree includes software. Alexander invites us to consider each requirement of an artefact as a light bulb which goes off only when the currently proposed design satisfies that requirement. For example, a kettle must be of adequate capacity, durable, not too heavy to lift, cheap to make, and many things besides. The initial design - a blank sheet of paper - actually satisfies some of these. A non-existent kettle never wears out, is easy to lift and cheap to make. So the light bulbs representing those requirements are off. However it does not have adequate capacity, so at least one light bulb is on. The design still needs some work.
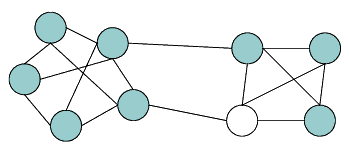
Requirements are interconnected. Let's say we redesign the kettle so it's made of finest titanium with a capacity of two litres. The capacity light bulb goes out, but titanium is expensive, so the cost light bulb comes on. Alexander models connections between requirements by connecting their bulbs. Each connection between two bulbs implies a certain probability that while one of the bulbs is lit, the other bulb will also light up. This represents the probability of breaking the connected requirement while trying to fix the original. (See Figure 1.)
|
|
Light bulbs and connections. Each bulb represents a requirement. When it is off, the requirement is satisfied. While a bulb is on, there is a possibility that each connected bulb may also come on. This represents the possibility that addressing one requirement may inadvertently break others. |
| Figure 1 |
A software product, like a kettle, is an artefact that must meet certain requirements. This is why we typically start off with a functional requirements document, or a set of stories and acceptance tests, or at any rate some kind of breakdown of what the product is actually meant to do. We can model those requirements as light bulbs and connections.
Let's look more closely at the connections between requirements. If not for connections, it wouldn't matter how many requirements a product had, because we could address them all as independent, trivial problems. This might take a long time if there were a large number, but the challenge would be perseverance rather than brainpower. At the other end of the scale, a product where every requirement was connected to every other - where work to address one requirement could potentially break all the others - would rapidly exceed the capacity of our limited human minds.
Light bulbs
Alexander illustrates these issues by considering various systems of interconnected light bulbs where, in any given second, there's a 50% probability of any lit bulb turning off and a 50% probability of a bulb coming on if its neighbour is on. For each system he asks how long, given an initial stimulus of a single bulb coming on, it will take for the ripples of illumination to die out - how long the system will take to reach an equilibrium state where every bulb is off. In software terms this is equivalent to asking how long after fixing a bug you'll be able to declare the work, and all its ramifications, finished. Unsurprisingly, the more numerous and stronger the connections, the longer it takes to reach equilibrium. In a system of one hundred maximally interconnected bulbs, Alexander calculates it will take longer than the lifetime of the universe for them all to go off. This equates to a never-ending cycle of design, realise you've broken some requirements, redesign, realise you've broken some more requirements, and so on. The lesson we can draw is that there's no point trying to address design problems with large numbers of densely interconnected requirements - we simply don't have the intellectual capacity to solve them.
Nevertheless, a glance at any sizeable requirements document will confirm that we frequently do address software design problems that have hundreds of requirements. The key, according to Alexander, is how effectively the system decomposes into independent groups. He calculates that a system of one hundred light bulbs decomposed into ten distinct groups - densely and strongly interconnected within each group, but not between groups - would take about fifteen minutes to reach equilibrium. Fortunately for us as developers, and indeed as humans, most of the design problems we face fall more into this latter category than the former. Their requirements decompose naturally into smaller subgroups which we can solve as more or less independent problems.
Software: requirements
Let's look at an example. An online retailer handles orders, which link stock items to customers who want to buy them. It's not hard to see how the functional requirements for this part of the product would decompose into groups for orders, items and customers (Figure 2).
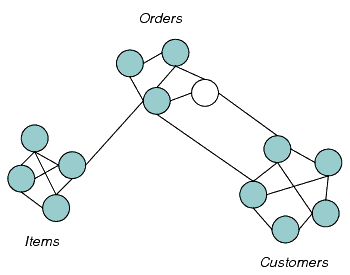
|
| Figure 2 |
The groups are not arbitrary. Each exists because the requirements cluster around an abstract domain concept, such as orders, items or customers. The domain concept explains why the requirements in each group are tightly linked, why work done to address one of them is likely to affect the others. Thus in many ways an Alexander-style requirements diagram like the one in Figure 2 is equivalent to a domain model, or models, from the world of domain driven design.
Alexander's approach, however, can give us more of an insight into the artefact's complexity. The number of requirements and the number, strength and pattern of connections between them gives us the basis of a less subjective measure of complexity, one we can use to compare different products and to compare different parts of the same product. We can expect it to have a real correlation with how much working on those areas will make our heads hurt.
Sadly it isn't adequate. I have worked on a number of products with broadly comparable complexity of requirements, and some of them have been a lot more painful than others. The number of requirements and connections between them tell us how complicated a product has to be - the necessary degree of complexity inherent in an artefact capable of satisfying all those requirements simultaneously. But by itself it does not completely measure the thing we wanted to measure: the size of the headache it will give us as developers.
The humble developer
Thus far we have focused almost exclusively on the artefact - the software. But what about the developer? Complexity is only a problem because the human mind has limits. We can only hold so many things in our heads at once. To understand the problem of complexity we must examine not only the artefacts but also the people who design them. What do developers do?
The bulk of our time as developers is spent implementing new features or fixing bugs. A bug means a requirement of our software product isn't satisfactorily met - a light is on. A feature means one or more new lights are 'plugged in' to the existing ones, with at least one of the new lights being on (otherwise there's no new work to do - the feature is already provided by the existing product). Our job as developers is to make all the lights go off again, to fix the bug or implement the new feature without breaking the implementation of any of the other features.
To do this we need to know not only which lights are currently on, but also which lights those ones are connected to. A connection between lights indicates a possibility that work done to address one might break the other. As developers we need to be aware of that possibility so we can check the corresponding areas of code and adjust them as necessary. For example, if I change how we store a customer's date of birth to accommodate a new feature, I might need to change connected parts of the existing code to compensate. If I miss a connection, I risk introducing a regression bug - a requirement which used to be met but which I've now inadvertently broken. We're all familiar with the cost of these, particularly if they go unnoticed until later stages in the production process. However there's also a cost to false positives. If I believe there's a connection when there isn't, I waste time investigating irrelevant code. This is harder to measure than regression bugs, but it nevertheless siphons off development time that could more usefully be spent implementing new, saleable features.
Of course it's not just the immediate connections that I need to worry about. If work on my immediate target causes a directly connected light to come on, then there's a chance that work done to turn that light off will trigger further lights to come on; and work on those further lights may in turn trigger others. I have to chase an expanding wave front of broken requirements through the code base. It's at this point that knowledge of the groups of requirements is very useful.
The groups can help
Groups of requirements exist whether we're aware of them or not. The online retailer system has groups of densely interconnected requirements for items, customers and orders regardless of whether I, as a developer, know that those groups exist or take them into account in my design and implementation. The fact that they do exist means that even if I'm not aware of them I'll probably reach a satisfactory design for the system eventually, turning all the lights off, because the wave fronts of broken requirements will be naturally limited. But the process is likely to be clumsy and time-consuming, tackling each broken requirement in a random order, constantly having to remember all the details of which lights are connected to which; and most likely getting it wrong fairly frequently due to the number of things I have to bear in mind all at once. The end result is usually features that throw up a barrage of unexpected extra work items as you implement them, then haunt you with regression bugs for months or even years afterwards.
If, on the other hand, you know which groups the immediate targets are in and how those groups relate to other groups then you can design a lot more rationally. You know that you need to consider the other requirements in the target groups, and pay especial attention to the points where those target groups connect to other groups - the interfaces. For example, on changing how we represent a customer's date of birth, I know I need to look closely at the code which implements the other customer requirements, and keep a tight grip on the interfaces between the customer code and other code which depends on it, preferably leaving the interfaces between them unchanged. I also know that I don't need to look at code which implements unrelated groups of requirements. This allows me to focus my limited development time much more closely on those areas where it's most needed.
Knowledge
So, to do a good job as a developer you need to know the connections between requirements and how they decompose into groups. Where does this knowledge come from?
There are three main repositories: external documentation such as design documents, requirement specs, etc; other developers; and the code itself. It's here that the ways in which software is not like a kettle start to become important. A kettle is typically designed once, probably by a single individual, based on requirements that change very little over time. Most substantial software applications, by contrast, are continually redesigned by an ever-changing team of developers to meet ever-expanding requirements. Under such circumstances you cannot rely on external documentation to stay up-to-date, or the other developers to have a full and accurate knowledge of how the system works. The code is the only thing that absolutely has to be complete and accurate, and moreover it's the only thing that you can guarantee a developer will have to look at to accomplish their work. This is not to say that documentation and other developers don't have an important part to play, but the code is the most effective repository of knowledge about requirements and how they decompose into groups. The easier you make it for developers to acquire this knowledge from the code, the better and faster they will be able to work.
Software: design
Let's look at a first draft design for the online retailer's system (Figure 3).
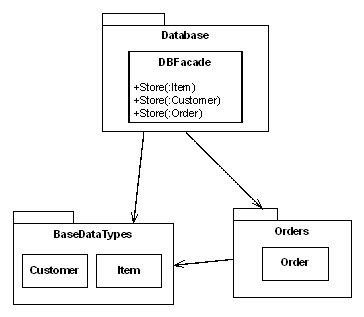
|
| Figure 3 |
The Customer and Item classes go together in a BaseDataTypes module because they're the basic system types, combining to make up an Order . I've also added a Database module because there are requirements that Customers , Items and Orders be permanently recorded.
There are two main things wrong with this design, things that might well flummox a developer coming fresh to the code. Firstly, the Database module implements each data type's persistence requirements. Effectively it implements a light bulb from each of the customer, item and order requirements groups. This is confusing because we now have to look in two places to identify all the requirements in each data type's group. Furthermore, it's not obvious that we need to look in two places. As a developer I expect a Database module to be about databases - integers, strings, tables, columns and whatnot. I don't expect it to implement requirements for Customers , Items and Orders . There's a fair chance that if I change one of those data types I'll forget to check that its persistence code still works, introducing a regression bug.
The second problem is with the BaseDataTypes module. It crowds together the Customer and Item implementations, suggesting to the unwary developer that the customer and item requirements might be connected. In fact, as we saw above, they are not. But because the code is together it may well take some valuable time to reach this conclusion. Moreover, a developer tasked with changing customer or item requirements will have to spend time hunting for the relevant code. 'BaseDataTypes' doesn't give you much of a hint as to what the module contains. Nor will it help much when deciding where new code should go. What exactly is a 'base' data type? Modules with this kind of ill-defined name often end up as dumping grounds for all manner of more or less unrelated code.
The above design makes it hard to find the groups of requirements by looking at the code. Even when you've found them, you have to constantly remember that Database implements some persistence requirements, and BaseDataTypes holds two separate groups. This uses up valuable brain capacity before you even start work. Of course in a small example like this it's not too much of a problem. But in large software products the burden of translating between the code on the screen and the working model in your head can become an enormous drag on development activity. In severe cases it simply takes too long to deduce a useful working model from the code and you end up hacking away blind, hoping the compiler will tell you if you do something wrong.
Software: design revisited
Let's have another go (Figure 4).
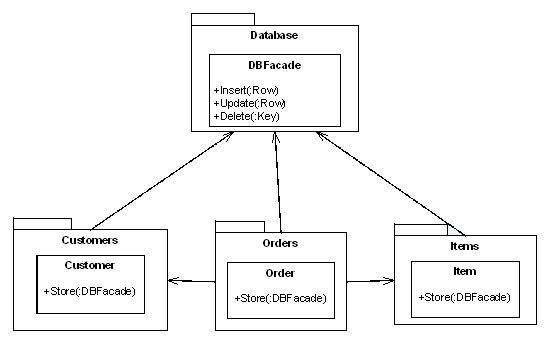
|
| Figure 4 |
The Database module now represents a database and nothing else. Each data type is responsible for storing itself in the database. The requirement groups for customers, items and order are now each implemented in a single module, rather than split across two, and it's easy to find where each is implemented because the modules are appropriately named.
There are still issues with this design. In particular it's questionable whether the data types should need direct knowledge of the database. Such inappropriate dependencies are often a good warning sign that there's further work to be done, and it's much easier to spot them if the modules themselves make sense. It's much easier to question why Customers depends on Database than why BaseDataTypes depends on Database , because it's much clearer what Customers is all about. Nevertheless, from a complexity point of view, this new design is a big step forward from what we had before.
Complexity and modules
We saw above that the number of requirements and the number, strength and pattern of connections between them serves as a useful measure of how complex a software product has to be, but is inadequate as a measure of how complex it actually is. It doesn't fully explain why some products make developers' heads hurt so much more than others. The missing factor seems to be ease of perception: how hard it is for a developer to perceive the requirements and their connections by looking at the code. The more brainpower you have to spend constructing and holding onto an accurate mental map of what requirements are implemented where, the less brainpower is left over to actually reason about them. You are more likely to make poor design decisions, increasing the complexity and making the next feature even harder to implement.
The obvious conclusion is that we should try to keep actual complexity as close as possible to necessary complexity - make it as easy as possible to see the requirements through the code. And it's particularly important to help developers identify the groups into which those requirements decompose. As our online retailer example demonstrated, modules have a vital role to play here.
A good module is one which implements all the requirements from a particular requirements group and no others, and is named after the abstract domain concept behind that group. Modules with these qualities make it very easy for a developer to see the requirements and their connections through the code. In our initial design above, none of the modules were good. The Database module implemented all the database requirements, but it also implemented requirements from the data types' groups. Correspondingly, Orders and BaseDataTypes were missing some of the requirements that rightly belonged to them. BaseDataTypes was trying to hold two unrelated groups; unsurprisingly therefore it wasn't named after any kind of recognizable domain concept. A good rule of thumb for module quality is to ask how easily, given its name, you could decide whether the module would be involved in any particular feature or bug. For good modules it should be easy.
In conclusion
Let's revisit the opening scenarios for a code base with good modules.
You have the requirements for a new feature. Your customers need it done on time. You start designing. The domain concepts used to describe the feature tie in naturally with the domain concepts used to name the modules, so it's easy to see which parts you need to start looking at and how they relate to the rest of the code base. Because each module represents a single, coherent domain concept it's proved easy for your colleagues and predecessors to add a little high-level documentation to each, so you quickly get to grips with any parts you don't already know. The time you save locating and understanding the code can now be spent designing your new feature; and you can do a better job because you understand that code more clearly. Ultimately you implement your feature faster and leave the code in a better state.
Of course there are still problem areas you want to refactor. Armed with a deeper understanding of complexity you can survey the code base for the worst areas. Which modules have incoherent names such as 'BaseDataTypes'? Where is the coupling between modules unexpectedly high, perhaps indicating that some bits of code are in the wrong place? Are there dependencies which don't sound right, such as Database depending on Orders , or vice versa? When you have a vision of what the code base should look like it becomes easier to identify and prioritize the problems and come up with appropriate solutions. Furthermore if your whole team shares the vision then all your refactoring efforts fit in with each other. A virtuous circle of reduced complexity and better design begins.
References
[Notes] Notes on the Synthesis of Form, Christopher Alexander, Harvard University Press 1974. ISBN 0674627512.

