








Today's languages force a one-size-fits-all approach on projects. Yaakov Belch, Sergey Ignatchenko and Dmytro Ivanchykhin suggest a more flexible solution.
'When I use a word,' Humpty Dumpty said in a rather a scornful tone, 'it means just what I choose it to mean - neither more nor less.' Lewis Carroll, Through the Looking Glass
When we started our most recent project, we had quite substantial discussions on the programming languages and libraries to be used and to our surprise found that, despite our very different backgrounds, we all agreed that existing programming languages are rather inadequate for certain aspects of otherwise pretty straightforward programming tasks. In our case, discussion started with rather routine issues like support for serialization and configuration, but eventually extended to much more complicated issues like the ability to write the very same code only once for several different programming languages (like C++ and Java) and compile-time detection of certain types of multithreading bugs.
The most substantial issue we have found in modern mainstream programming languages like C/C++/Java, was that they are mostly languages aiming to instruct a computer what it should do, but what we needed was a language which provides a straightforward and easy way to express our thoughts. While certain thoughts can, indeed, be directly expressed with modern mainstream programming languages, there is still a wide range of thoughts and concepts which require rather artificial, inefficient or outright mindless and repetitious coding to be done. We feel that the worst part about it is that it tends to affect developers' way of thinking, causing a developer to pay more attention to how to get around language/compiler/library problems rather than to think what the program logic should do, with the worst case being the developers' attempts to redefine the original task, and degrading the end-user experience merely because of language or library limitations 1 .
Another way to represent the same basic idea is to consider it as a way to shift the burden of repetitive, mundane tasks from developer to compiler, freeing developers' time for more creative work. As a common wisdom says, ' Computers will never do anything really smart for you. But they can do something dumb, freeing you some time to do something really smart '.
As a result of all those discussions, we have tried to find out if there is some way to address the limitations of modern mainstream programming languages while keeping their positive aspects substantially intact, and taking into account certain practical aspects of organization of medium- to large-scale programming projects.
Current practice - project-specific vocabularies, guidelines and problems resulting from lack of their enforcement
In practice, every medium- to large-scale software project has its own project-specific vocabulary as well as formal or informal usage conventions and guidelines.
Such vocabularies include class hierarchies, APIs, macros and templates. For example, for Apache projects there is an 'Apache Portable Runtime' library, which forms a substantial part of Apache projects' vocabulary, and the 'Linux Kernel API' forms a substantial portion of the vocabulary for writers of Linux drivers. Current programming languages provide means to manage and control such vocabularies.
However, conventions and guidelines for the correct use of project-specific vocabulary are no less important, and existing programming languages usually don't provide much help for managing and controlling them. In an average medium-size software project there are many implicit conventions as well as formal or informal guidelines, which are at best documented (within source code comments or a separate document), and at worst exist as an undocumented bunch of 'everybody knows it' rules which are passed from one generation of developers to another, often only via trial and error. Even if there is the will to enforce those conventions and guidelines, missing support from the programming language easily leads to dilution of those guidelines, in extreme cases up to the point of the whole project becoming one big plate of spaghetti code, with the need to throw it away and restart the whole project from scratch.
For example, if the project is designed to be cross-platform but is compiled only on one platform for the time being, there is usually a guideline 'never ever use platform-specific APIs'. Another typical example of guideline is 'Resource Allocation Is Initialization' (RAII), which aims to reduce/eliminate resource leaks. Unfortunately, as there is no way of enforcing these guidelines, project architects tend to find that the burden of such strict self-discipline proves to be too much for at least some of developers. As a result, in the case of the 'no platform-specific API calls' guideline, architects either need to spend a significant portion of their time to 'police' the code for inappropriate API calls, or find when they want to compile the project elsewhere that it will require major refactoring, up to the point of complete rewrite. Effects of violating 'RAII' guideline are usually less devastating, but still can easily lead to many months spent on isolating and fixing resource leaks. To make things worse, not enforcing guidelines leads to new developers seeing code which does not comply with the guidelines, assuming that this code is OK and then using it as a model. The very same thing happens with virtually any non-enforced guideline - it takes significant effort to keep it from being violated, and if this effort is not made, it usually means a downward spiral towards a complete ignoring of the guideline.
Therefore, it seems beneficial to provide some way to enforce project-specific guidelines; we will discuss more detailed requirements for such control below.
Requirement - need to restrict language features at least in certain cases
Developments in programming languages are very often related to adding more and more features to the language. As one of the most prominent examples, the new programming language 'D' [ Alexandrescu09 ] takes C++ (which is already very far from being simple) and adds an impressive number of new features to it (from garbage collection to closures). Planned developments for the C++ standard [ ISO09 ], while are less impressive in scope, also include a number of new features, including lambda-functions. While we agree that there are some projects which do need those features, we want to show that restricting available language features can be a good thing, at least in some cases.
First of all, let's take a look at the non-programming world. Even at first glance it becomes apparent that excluding certain words from vocabulary can help to keep language clarity; one notable example is 'Seven dirty words' banned on American TV; while their prohibition obviously restricts available vocabulary, it is quite difficult to argue that at least in some contexts agreement on not using them indeed promotes language clarity rather than impeding the expression of thoughts 2 .
Now let's see how it applies to programming languages. Take as an example a project designed to be cross-platform and the unenforced guideline 'never ever use platform-specific code' (see above). It seems quite obvious that the ability to enforce this guideline (restricting programmers from using platform-specific language features) would benefit that hypothetical project.
Moreover, from our observations of trends within the industry we have found that, ironically, the more features a programming language provides and the bigger the project it is used for, the more project architects will be cautious and reluctant to adopt it exactly because of increased efforts to enforce guidelines. For example, we see the (in)famous Linus Torvalds' post 'C++ is a horrible language' [ Torvalds ] as a prominent example of such reluctance of a project architect to move to a language with more features. In particular, Linus wrote: ' You invariably start using the 'nice' library features of the language like STL and Boost and other total and utter crap, that may 'help' you program, but causes... [here follows list of problems] '; we think that if Linus could choose which features of C++ to allow into git or Linux kernel and which not to allow, he would be much less reluctant to allow a feature or two from C++ (but just those 2 features he needs, not more) into Linux kernel or git.
Requirement - need to provide more language features
Another problem of existing project-specific vocabularies is that usually they are just vocabularies, not real languages. It means that basically you can specify 'words' to be used, but cannot really specify the patterns they can belong to. Even for now ubiquitous classes, while you can easily specify acceptable APIs, there is usually no way to enforce at compile-time that, for example, the function init() must always be called before any other function (excluding the constructor), or that the function deinit() must always be called right before the destructor. When dealing with features which cannot be easily described in terms of classes, the situation is even worse. For example, let's consider MFC's 'message cracking' which uses macros like DECLARE_MESSAGE_MAP , BEGIN_MESSAGE_MAP and END_MESSAGE_MAP . While it indeed provides a way to define message maps, they are far from being easily readable, and the error messages the compiler gives about malformed message maps tend to be perfectly useless (which is inevitable as compiler operates at the stage after the preprocessor). Add to the mix the not-100%-efficient code it generates (which was the case last time we checked), and you'll get a typical pattern of the effects of emulating a missing language feature without the direct support of the language.
There are many such missing features in different languages, with the obvious examples of reflection and serialization being just the tip of the iceberg.
Adding all of those new features into the same language doesn't look like a good option either. Take serialization, for instance. Some can say, ' wait, languages like Java already have it, so let's just switch to Java ', but unfortunately it won't always help. Java indeed provides built-in serialization, but the problem is that it is only one of many possible serializations , and if you need, for example, ASN.1 [ Larmouth99 ] serialization (and don't forget about at least the BER and DER variations), or JSON serialization, or even IIOP serialization (not 'RMI over IIOP', but real IIOP) at some point, developers will still need to code it manually (which requires substantial effort even for medium-sized projects). It means that to satisfy all requirements for all possible projects, language will need to provide support for all possible serializations, which most likely is not feasible.
Resolving requirements conflict - a call for cheap creation of project-specific languages
At this point we seem to have two conflicting sets of requirements for the programming language. One set of requirements calls for restricting features, another one asks for adding more and more new features. Fortunately, it seems that there is a way to satisfy both those sets of requirements simultaneously; it is to allow different projects to have their own different languages. While such an option to create project-specific languages has existed for a long time (using tools like YACC), apparently the cost of language creation was too high for real-world projects. It means that the way to create such a new project-specific language should be substantially cheaper than that of YACC to become usable in practice.
Also we should emphasize that here we're not speaking about domain-specific languages, we're speaking about project-specific languages, where every single project should have its own programming language (or more likely, programming language dialect). It obviously makes the requirement for development of such a language to be cheap even more important.
Requirement - support for architect's role and control over features
In practice, in order to succeed in building a software project with more than 2-3 developers, a project usually has one or more project architects. The distinction between architect and developer roles is vital to the success of the project, but unfortunately there is no direct support for such distinction in modern software languages. From our own experience and discussions with project architects within the industry, it becomes quite clear that architects would clearly appreciate having more control over the language features allowed for use in their specific project.
The most important reasons why architects want to control language features are:
- Ability to enforce a common style for the project, reducing potential misunderstandings between team members. The bigger the project, the more likely developers will need to work with code written earlier by some other programmer. Even if some piece of code is trivial to the author, it may well be incomprehensible by others, especially if their coding style is substantially different. And here we don't mean 'style' as the way to indent curly brackets, but rather 'style' as the approach to solving certain types of problems.
- Ability to enforce common requirements for the project, aiming to stimulate a more efficient coding style, where efficiency can be measured in terms of CPU/RAM, bugs or security flaws per thousand lines of code, or development time spent on a certain feature. The problem here is that different projects have very different aims, and no approach works universally well for everybody; eg a coding style which is good for writing a Flash-based Tetris game will probably be devastating for Linux kernel (and vice versa).
- Ability to prevent 'vendor lock-in'. When you start using some non-standard feature of one platform or tool, you may soon be unable to switch to a competing platform or tool. The advantage of this one feature right now may turn out to be much smaller than the advantage of using a more appropriate tool later on.
One of the important aspects of control over language features is the ability to use different sets of rules for different parts of the project. For example, it is fairly obvious that the set of rules and/or guidelines for server-side business logic code will be quite different than those for the UI code within the same project.
It is worth noting that support for the other roles which exist in modern projects (most notably the 'Business Analyst' role) can also be achieved using the same mechanism, creating special dialects easily usable by the target group.
Requirement - 'Agile programming language'
In recent years, agile software development [ Agile01 ] [ Newkirk01 ] has become more and more popular among software developers, and we think this is no coincidence. One of the biggest reasons for its efficiency is that modern business requirements tend to evolve much more rapidly than the program can possibly be developed, which implies that the ability to react to the changing requirements is extremely important for the success of the project.
We feel that the very same logic should apply to programming languages too. Currently, choosing a programming language is basically a 'once and forever' decision, which is made very early in the development process (essentially this is a 'waterfall' decision with no ability to change it later). Ideally, we think that the project language should be able to evolve as the needs of project grow.
For example, one of us as an architect prefers to start projects with a minimal vocabulary provided to the developers, and then when a requirement for a new feature arises the developer is able to come to the architect and to argue that a certain language feature should be introduced. Our ideal 'Agile programming language' should support this development model (allowing to introduce new language features along the road) and as well should support any other model when the programming language needs to evolve with the project.
Extending our earlier analogy, we should note that language on TV also evolves as the time goes on. Certain things, which were off limits 10 years ago, have become mainstream now, certain words have gone out of circulation, and new words have been invented. The very same process is natural for any successful software project which lives for many years.
Requirements - industry 'use cases' for project-specific languages
One of the important factors to consider when trying to design something is to understand its potential uses within the target industry. Our preliminary analysis has revealed several areas where project-specific languages could be useful. This analysis was the basis for our programming language discussed later, which (as we hope) should be able to cover all these areas by using language extensions/dialects. These areas include:
Bigger projects, where keeping the language clean is a significant concern
Actually, we think that almost any project which has more than one developer can benefit from enforcing currently informal (and therefore unenforced) guidelines. Still, usually the bigger the project, the more significant the requirements to keep the code clean tend to become. Ability to enforce guidelines will help improve code readability and clarity, while keeping necessary requirements like portability (if it exists) under control, without spending ongoing significant effort on enforcing them.
Examples of requirements for such projects can include:
- Portability: don't use features that are not provided by all target platforms
- Avoiding vendor lock-in
- Abstractions at the proper level and efficient implementation on each platform
- Avoiding constructs which are deemed inefficient by the project architect (as discussed above, definition of efficiency depends on the project, ranging from CPU efficiency to development efficiency)
- Enforcing naming conventions
- Forbidding use of confusing language features (with the list of confusing features being up to project architect)
- Replacing macro-preprocessor and/or templates by more predictable mechanisms
- Replacing pointers with alternative abstractions, like references and arrays. We understand that this item is rather controversial and will probably cause a lot of opposition from existing C/C++ programmers, but as long as it is only an optional feature, we don't see it as a big problem.
Projects with high requirements for security and/or reliability
We feel that enforcing certain existing guidelines can substantially improve both program security and reliability. Examples of such guidelines include:
- Limiting access to certain resources (like the file system and network)
- Preventing buffer overflows
- Addressing resource leaks
- Preventing at least some kinds of multithreading bugs (which tend to be extremely difficult to find)
Projects with a need to extend an existing language
It is fairly common that projects are happy with C/C++ or Java, and need just a few minor adjustments to make life easier. Examples of such new features include:
- different serialization mechanisms (from IIOP and JSON to custom storage-optimized or legacy-system-compatible ones)
- Built-in testing support
- Design By Contract
- Introspection
- Nested functions
- Anonymous functions
- Closures and lambda-functions
Projects which need inter-language portability
Sometimes a project needs to be compilable across multiple languages. Usually it applies to the C++/Java pair, to make sure essentially the same logic can run optimally on both C/C++ platforms like Windows/Linux/Solaris/... and on Java-only platforms like in-browser JVM, Android or BD-J. Achieving this goal will most likely require to use a 'Replace pointers' dialect.
Projects with a need for user-definable scripts
Usually projects which need user-definable scripts, tend either to invent their own script language, or to use an existing one (such as JavaScript). Ideally though, it often should be a rather close dialect of the very same language within the program itself, and in part allowed to the user. Example requirements for such projects can include:
- Should be easy to learn
- Should be easy to integrate
- Should be easy to transfer features from the 'compiled-into-the-program' domain to 'user-definable' one.
- User dialect might even need to be a weakly typed one
UI projects
We feel that current state of programming is pretty sad in the field of UI projects. For example, all the UI code written for Apple Cocoa API, is essentially useless for any other platform, and the very same is true for most of the platform-specific APIs (obviously including the Windows API). One can argue that Java provides a good solution for a cross-platform UI, but our understanding of ideal cross-platform UI is much wider then just an ability to run a client-based UI on different platforms.
Within our philosophy that 'language is to express thoughts', we understand portability in much wider sense. We think that in most cases it is indeed possible to create a UI which is suitable not only for an application on an end user's PC, but also for a completely different media.
Example requirements for such projects can include:
- Portability across different platforms
- Portability to use with remote-access protocols like VNC
- Portability between client-based UI and web-based UI
- Portability to text UI where applicable (obviously, you cannot make PhotoShop work in a text-only window, but we feel that the UI to install an OS security upgrade should translate into text easily).
Summarizing requirements
It seems that now we can summarize requirements for a programming language that will address the issues we have outlined above. This programming language should:
- allow creation of project-specific language dialects, including
- ability to restrict certain existing language features;
- ability to add new language features;
- ability to apply somewhat different requirements to different subprojects
- have low cost of creation for project-specific language dialects mentioned above;
- be 'agile', allowing ability to create project-specific language dialects as the need arises, not necessarily at the very beginning of the project;
- have explicit (but optional) support for 'Architect'/'Developer' distinction
- keep the positive aspects of existing programming languages;
- preferably including easy readability for those with experience of existing languages.
In the rest of this article, we will propose a way to address all of those requirements. It is to define a 'basic language' (based on some existing and popular language) and to allow extensions to be written for it easily (much more easily than it can be done now with YACC). As the library of such publicly available extensions grows, project architects will be able to choose their project-specific dialect mostly by choosing which extensions to this 'basic language' they want and which ones they don't want; this should make dialect creation even cheaper.
Consideration - comparing programming languages' popularity
As one of our requirements is to keep readability for users of existing programming languages, we need some data on programming language popularity to understand what kind of syntax is the most popular one (and therefore will be the most easily recognized). We took the popularity of projects on SourceForge [ Labelle ] as a baseline (adding a new point for 2009, see Figure 1.), and have found that at least over last 8 years, programming languages with C-like syntax 3 , were used for at least 80-90% of all the SourceForge projects. This data is also corroborated by independent research [ DedaSys ]. Therefore, we can safely assume that C-like syntax is quite universally recognized in the industry, and using it as a baseline will have substantial benefits at least because of this universal recognition.
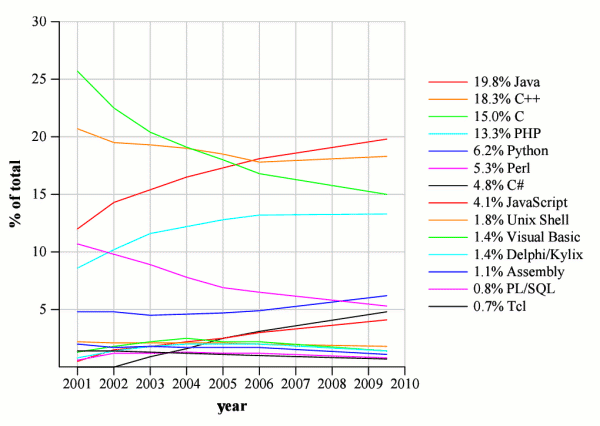
|
| Figure 1 |
Based on this research, we have decided to use a subset of a C++ (close to 'C with classes', [ Stroustroup94 ]) as our 'basic language', and to name it 'C+-', to show that it provides options to be either more feature-rich, or to be less feature-rich than C or C++. C+- will also allow language extensions (to form language dialects) but they will be restricted to similar syntactic patterns.
It's important to note that in C+-, we do not support all of the subtleties described in the C++ standard (even the C standard is not 100% implemented, though most of the features can be reinstated using C+- extensions). Instead, in certain situations we require the programmer to use simpler alternative methods to express the same thought. According to our experience, most programmers 4 already tend to avoid most of these complexities and opt for simpler alternatives. Hence, we feel that our limitations don't substantially reduce the usability of C+-. This issue will be discussed in more detail below.
Consideration - common extension types
Based on the 'Industry use cases' above, we tried to analyze what different types of extensions might be needed, and our analysis has revealed that virtually all language extensions and dialects we could think of fall into one of two classes:
- Limit or forbid use of a certain feature/feature combination in C++. Sometimes, this involves complex program-scale checks to detect such usage (for example, it might involve memory leak detection during compile-time; while it's not always possible, some memory leaks can indeed be detected, with the expected number of cases detected being significantly higher than that of LINT [Kunst88]).
- Copy a proven feature from another language. In some cases, this will require removing conflicting features from C/C++.
Researchers from the field of domain-specific languages may be surprised by the virtual lack of demand for completely new features. This industry inertia may be explained by the following observations:
- The chances of misunderstandings and inconsistencies grow quickly with project and team size. Enforcing even simple rules in medium to large projects is a much more pressing concern than in small projects.
- Even in the most innovative projects, the innovation is usually contained in a few modules and complemented by a larger amount of existing industry code.
- It is natural for managers to limit the risk of a large project by mainly using ideas and tools that have been tested in smaller projects before. Even when they are not perfect, this experience will help to avoid problems in planning and to resolve problems when they occur.
Technically, C+- does allow completely innovative extensions, but we expect more conservative extensions to dominate.
Consideration - what to compile to?
Whenever somebody wants to develop new programming language, they usually face a tough question of 'how we're going to compile it on all existing platforms?'.
Fortunately, as we feel that there are already lots of languages which 'tell computers what to do' rather efficiently, we didn't aim to compile C+- code directly into binary code. Instead, we are aiming to compile C+- into the source code of a certain 'target programming language', such as a C/C++/Java; we also aim, where possible, to make this 'target programming language' code be human-readable, and to correspond line-to-line to the original C+- code. This approach has the additional benefit that the same framework can be used to compile C+- code into languages like C and Java, which are similar source-wise but are rather different binary-code-wise. This approach does not preclude us (or anybody else) from developing a 'native' compiler at some point later.
Implementation - 'Basic C+-', extensions and dialects
C+- is essentially an extensible language, consisting of 'Basic C+-' plus all kinds of different extensions to it. Language extensions can be combined together to form 'C+- dialects', specific to the project. Extensions themselves are also written in one such C+- dialect (specific to the task of writing language extensions).
It is important to note that technically a very wide range of extensions can be created for C+-, with some extensions even breaking the overall 'feel' and readability of C+-. To address this problem and avoid too much dilution of the meaning of 'C+-', we intend to disallow certain extensions from being named 'C+- extensions' (such extensions and dialects will still be possible, but without 'C+-' being attached to the name of the resulting language/dialect). We also intend to discourage different extensions from doing essentially the same thing and encourage authors to consolidate their efforts to avoid unnecessary duplication. This corresponds to our feeling that differences in language dialects should be motivated by different needs, not by a need to differ.
Implementation - 'Basic C+-' as a subset of existing C/C++
We tried to make Basic C+- more or less 'the least common denominator' of the most popular programming languages; this logic has lead us to making our language rather close to 'C with Classes' [ Stroustrup94 ], but with certain technical incompatibilities with C.
These incompatibilities include:
-
a*b; // error - binary expression as a statement
-
A x[3][]; // OK int (*ptrToFunc)( int, int ) = NULL; // error: // "complex" type in variable declaration; // need to use the following instead: typedef int (*)( int, int ) FuncPtr; // OK FuncPtr ptrToFunc = NULL; // OK
-
A* xx = (A*)x; // error // C-style cast is not supported, // need to use the following instead: A* xx = c_cast<A*>( x ); // OK, c_cast<> // is similar to the C++ *_cast<> family of casts
-
int x = sizeof(a*b); // error; // sizeof(expression) is not supported; // only sizeof(type) is supported now
While we have quite strong feelings about items (1) and (2) and they are unlikely to be introduced later (as we don't feel obligated to support what we feel is a 'cumbersome and obfuscated coding style'), items (3) and (4) can be reinstated at some point if there is enough pressure from the community to do so.
As of now though none are supported by C+-, which made the initial implementation much easier; in particular, these restrictions allowed the grammar of C+- to be a LALR(1) grammar , substantially reducing the cost of initial implementation.
Another problem such an extensible language can face is the pollution of the namespace of global keywords with extension-introduced keywords. To address this issue, we plan to impose the following guideline on official C+- extensions (those which can have 'C+-' in their name): any keyword accepted by the parser must either:
- comply with the current C, C++ standard, or
- start with a leading @
While exceptions are possible (for example, c_cast<> is likely to be introduced without @ to be consistent with the C++-style *_cast<> family of casts), in general we're going to apply this guideline both to our own and to 3rd-party extensions.
Implementation - extension example
C+- aims to achieve the agility and flexibility requirements via the wide use of language extensions. Let us consider one rather simple (but practical) C+- extension.
There is one common problem with multithreaded programming, which C+- can help with. Let's assume that we have a C++ program with the following model of synchronization between threads. There is class Mutex and class Lock with constructor Lock( Mutex& mx ) . Lock() acquires mutex mx in the constructor, and releases it in the destructor; this simple technique protects developers from forgetting to release Mutex . But the very next problem developers face is that of making sure that they didn't forget to protect all accesses to all variables which need to be protected, by creating an instance of Lock for the appropriate Mutex . In practice, such mistakes can live unnoticed for many months and will manifest themselves at the worst possible time, causing a lot of time to be spent figuring out what went wrong. As the job of checking that all accesses to all relevant variables are protected looks rather mechanical, we will try to write a C+- extension to handle it.
First, let us describe what we want to achieve. We want to create an extension which will allow us to write a modifier
@protected_by <mutex_name>
for any data member, and it should then become the job of the compiler to check that every function which accesses one of those 'protected_by' variables, has a Lock object created for the relevant Mutex (in practice, more sophisticated analysis of the call graph will be necessary, but for the purposes of this article we will restrict the task definition to a single function only).
Then our hypothetical extension protected_by will look something like Listing 1.
@extension protected_by {
@additional_node_member
string protected_by default "";
// provides us with a data member 'protected_by'
// in each node of the parsed semantic tree
@data_member_modifier @protected_by IDENTIFIER
{ protected_by = identifier_name( $1 ); }
// assigning data member defined a few lines
// above
@data_member_access_hook( Node& node )
{
Node& decl = find_data_member_declaration( node );
if ( decl.protected_by == "" )
return;
for ( Node::going_up_code_iterator it =
node.begin_going_up_code();
it != node.end_going_up_code(); ++it )
// going_up_code_iterator goes "up" the code
// until it encounters function definition
{
Node& n = *it;
if ( n.nodeType() == Node::ObjectDeclaration
&& n.objectType().name() == "Lock"
&& n.nParameters() == 1
&&
test_reference_to_data_member_equivalency(
n.parameters[ 0 ], node )
)
return;
}
report_error( ... );
}
};// @extension protected_by
|
| Listing 1 |
It is rather obvious, that such an extension (even when production-quality code) will not have 100% accuracy in detecting both mistakes and absence of mistakes. It is fairly easy to write code which will make any such static analysis impossible, leaving room for situations for which it cannot possibly be decided for sure if they provide locking or not. Our approach in this (and many similar cases, like detecting memory leaks) is to:
- admit that for any such analysis there are 3 possible outcomes: 'good', 'bad' and 'not sure'
- in general, aim for '100% safe' code, treating 'not sure' the same way as 'bad'. This behaviour can be overridden by the project architect if really necessary. Our estimates show that in at least 90% of cases it should be possible to rewrite the code into a 'good' form (as an additional benefit, such a rewrite tends to make the code cleaner). In those rare cases when the code indeed needs to be so complicated that 'not sure' situations are indeed necessary, such code can always be moved to a separate subproject with a different set of restrictions, or in some cases extensions might need to be customized for the specific needs of specific project.
Obviously, many other types of extension are possible within C+-. It includes extensions to add new language constructs like functional-style map() , reduce() and filter() , though the ability to affect operator precedence or introduce new operators is not currently planned both because of the language dilution issues and because of technical complexity.
Implementation - combining extensions and agility
As we hope, most of the power of C+- extensions will come from the publicly available library of extensions, and project architects will mostly just select a set of features they want for their specific project (or a subproject) forming a project (or subproject) dialect. This creates a very agile language, where certain constructs can be added as easily as by checking a checkbox and recompiling the compiler. Obviously, we cannot hope that 100% of all cases for all projects will be covered by existing extensions, and from time to time some project-specific extensions will need to be written; we still hope that with all the measures we have taken to make writing such extensions simpler, it will still be quite within the abilities of even rather small projects (especially as it will always be possible to start without certain extensions and introduce them later as the need arises).
Such variety of extensions means that the problems of combining extensions will be very important for the future of C+-. Fortunately, it seems that as long as:
- all extensions start with an extension-specific keyword
- extensions are limited either to restricting a single feature, or to introducing a new one, inter-extension interaction will be reduced to a minimum, essentially allowing most extension combinations to be valid. We have about 30 extensions we ourselves would like to have on our list, and almost all of them can be combined with the others easily (with one notable exception being an extension to replace pointers with references and arrays).
In any case, C+- extensions will be checked for incompatibilities as early as possible, and project architects will know that they selected an impossible set of extensions at the stage of selection.
An essential part of C+- is an ability to have different subprojects with different dialects and still be able to compile it all together. To deal with this, C+- will require that each source file starts with a line declaring the language dialect used in this file. The set of available dialects and their names are specified by the project architects.
Implementation - 'BetterCC'
To enable the writing of C+-, we needed to create a comiler to generate the dialect compiler; we have named it 'BetterCC'.
Basically, BetterCC is a platform to create different languages and dialects, with C+- being just one of a multitude of possible languages. We intend to license BetterCC for free under an open source licence. On the other hand, as it was already mentioned above, we feel that we need to exercise control over C+- extensions to avoid unnecessary language dilution.
BetterCC is implemented using common approaches and consists of the following stages (with extensions allowed to interact with this process via various hooks):
- lexer: split sources into tokens
- parser: detect language structures; build a semantic tree
- resolver: build symbol tables and attach full semantic information to the nodes of the semantic tree
- target writer: convert semantic tree to the target language (e.g. C++)
- target compiler: compile target code to objects or executables.
While some of these stages (e.g. lexer and parser) may interleave in execution time, we avoid as much as possible pushing information back into previous parts of the pipeline. In particular, we do not allow the lexer to read symbol tables to determine the semantics of a non-keyword identifier.
It's interesting to note that most of the projects will involve two very separate runs of the stages above. The first run happens when project architects have defined which extensions they want, and then BetterCC is used to compile these specifications (written in special C+- dialect designed for writing extensions) into a 'project compiler'. The second run happens within this 'project compiler' when developers compile their C+- code (in the dialect defined by project architects) into the target language.
Implementation - C+- and preprocessor
While we consider the preprocessor as a relatively minor issue, we expect it to be rather frequently asked about, so we'll try to address it quickly here. Basically, we feel that a preprocessor as 'something that runs before the compiler' is not a good thing. On the other hand, we recognize the need for things like conditional compilation. To deal with it, we performed some analysis of existing code, and found that in well-organized and well-disciplined projects developers normally use the preprocessor as a just yet another idiom from the 'project vocabulary'. For example, constructs like
#ifdef THREADS
....
#else
....
#endif
usually becomes ubiquitous all over the project, to denote 'part of code which is compiled only if we're compiling for multithreaded mode', which makes it essentially an idiom which belongs to the 'project-specific language', rather than a preprocessor trick.
Based on this analysis, we have decided that there will be no preprocessor in C+-, but there will be an extension which will allow for easy creation of language idioms like the one shown above. Among other things, this approach will improve project discipline and also will allow for much stricter enforcement of certain rules at compile-time.
Implementation - compatibility with existing languages
Obviously, when one starts a new language, there is always an issue of reusing existing libraries written in different languages. In this area we plan to allow a project architect to choose one of two approaches:
- rely on cross-platform and cross-language C+- libraries, ensuring portability, avoiding vendor lock-in, etc. While we plan to provide a certain set of such libraries, C+- will need support from the programming community to make this set of libraries comprehensive enough.
- to reuse existing libraries in existing programming languages. While this approach does not ensure a high degree of portability, and we hope to be able to discourage using it at some point, C+- will need to support it at least for a while. To facilitate it, we plan to have an import tool which will import, for example, C/C++ headers into C+- headers; then, when compiling C+- into C/C++, it will generate source code which is C/C++ and will directly use appropriate C/C++ functions/classes. This approach won't be restricted to C/C++; the very same thing can be done with Java (though compiling to Java as such will require some special extensions to C+-, eliminating pointers from C+-).
Conclusion
We think that we have managed to find a solution which, while is not absolutely universal, can help both academics and industry with common problems. The advantages of the proposed approach compared to existing programming languages are:
- cheap creation of project-specific language dialects
- 'agility' to easily add/restrict language features as necessary
- explicit (but optional) support for 'Architect'/'Developer' distinction
All of that was achieved without affecting the existing positive aspects of successful existing programming languages too much. We think that we have managed to keep most of the most popular syntax, and most of the concepts, while moving towards the 'a programming language is to express thoughts, not to tell a computer what to do' paradigm. We hope that going this way will save valuable developer time currently spent working on issues which are purely mechanical or can be done mechanically, and start spending it on tasks and algorithms in hand, which we think will be more interesting for most developers and useful from the point of view of end-results too.
Currently we are in the process of implementing these ideas in practice and hope to present the first working implementation of C+- soon. n
References
[Agile01] Kent Beck, Mike Beedle, Arie van Bennekum, Alistair Cockburn, Ward Cunningham, Martin Fowler, James Grenning, Jim Highsmith, Andrew Hunt, Ron Jeffries, Jon Kern, Brian Marick, Robert C. Martin, Steve Mellor, Ken Schwaber, Jeff Sutherland and Dave Thomas, 'Agile Manifesto', http://agilemanifesto.org/ (2001).
[Alexandrescu09] Andrei Alexandrescu, The D Programming Language, Rough Cuts, Addison-Wesley, 2009 [work in progress].
[DedaSys] DedaSys LLC, 'Programming Language Popularity', http://langpop.com/
[Graham03] Paul Graham, 'Five Questions about Language Design', http://www.paulgraham.com/langdes.html (2003).
[ISO09] ISO, Working Draft, Standard for Programming Language C++, ISO/IEC, N2914, 2009
[Iverson79] Kenneth E. Iverson, 'Notation as a Tool of Thought', 1979, ACM Turing Award Lecture.
[Kunst88] Frans Kunst, 'Lint', a C Program Checker, Vrije Universiteit Amsterdam 1988
[Labelle] François Labelle, 'Programming Language Usage Graph', http://www.cs.berkeley.edu/~flab/languages.html
[Larmouth99] Prof. John Larmouth, ASN.1 Complete, Open Systems Solutions, 1999
[Newkirk01] James W. Newkirk, Robert C. Martin, Extreme Programming in Practice, Addison-Wesley, 2001.
[OCC] International Obfuscated C Code Contest, http://www.ioccc.org/
[SE] Simplified English: http://en.wikipedia.org/wiki/Simplified_English
[Stroustroup94] Bjarne Stroustroup, The Design and Evolution of C++, Addison-Wesley, 1994
[Torvalds] Linus Torvalds, 'C++ is a horrible language', http://thread.gmane.org/gmane.comp.version-control.git/57643/focus=57918
1 The idea that the language used by people can affect the way they think is nothing new, and in non-programming world is known as 'Sapir-Whorf Hypothesis'. While we're not aware of extensive discussions of its applicability to programming languages and developers, some observations implying such applicability were made by Iverson [ Iverson79 ] and Graham [ Graham03 ].
2 Late during review the real-world example of Simplified English was suggested [ SE ].
3 Languages C, C++, C#, Java, PHP, Perl, JavaScript (and many more) all are using common syntactic structure borrowed from classic C: operators with generally accepted precedence levels, nested curly brackets and commonly accepted control structures like if-else , while , for etc.
4 Obviously excluding those who're competing in the 'Obfuscated C Contest' [ OCC ]

