








An essay on paradigms, refactoring, control flow, data, code, dualism and what Roman numerals ever did for us. Kevlin Henney takes us on a whirlwind tour.
Looking at something from a different point of view can reveal a hidden side. With physical objects this hidden side can be literal, hence why technical drawings of three-dimensional objects are often made using a multi-view projection, such as a plan view and elevation views. With abstract concepts the hidden side is more figurative. In software architecture, for example, view models, such as 4+1 [Kruchten95] or ODP viewpoints [ODP], can be used to bring different concerns of a system into focus, such as user interaction, governance, behaviour, code structure, information model, physical distribution, infrastructure, etc.
Numeral systems also have this quality. Changing how numbers are represented doesn’t change the numbers represented, but it does change how we think about them. Thinking about integers in binary, for example, reveals different patterns (and failures) than when we think about them in decimal. Binary also chunks more easily into hexadecimal. Thinking about RGB triplets makes more sense in hex than in decimal. And so on. Changing base can reveal new possibilities [Deigh17].
The same shift in perspective is also possible moving from a positional system, such as the common Hindu–Arabic system for decimals [Wikipedia-1], to one based on abbreviations of values of different magnitudes, a sign–value system (sign in the semiotic sense of symbol rather than as a positive/negative indicator) [Wiktionary], such as Roman numerals [MathsIsFun]. And somewhere between these two numeral systems – and more globally – we find the abacus, a bi-quinary coded decimal system [WordFriday] (like Roman numerals), built on a simpler sign system, but organised positionally (like the Hindu–Arabic system) to enable rapid arithmetic.
The Roman numeral system was used across Europe before the widespread adoption of the Hindu–Arabic system. It was perhaps more uniformly standardised following the fall of the Western Empire than during the heyday of Roman rule.
That would be the end of the history lesson if it were not for the persistence of the numeral system long after the Renaissance and into the modern day. The most likely places you will encounter Roman numerals these days include old buildings, analogue clock faces, sundials, chords in music, copyright years for BBC programmes and coding katas for programmers [Wikipedia-2].
The standard form can comfortably represent 1 to 3999 (I to MMMCMXCIX), although sometimes 4000 and beyond can be expressed (with 4000 as MMMM); numbers beyond this range would typically have been written as words, and would often be approximated. There was no notation for zero – or even a concept of zero as a number – so in medieval texts this would have been written as nulla or abbreviated to N. And, without zero, there were certainly no negative numbers.
It works, but…
The Python code in Listing 1 shows one way of converting a number to a corresponding string of Roman numerals.
def roman(number):
result = ""
while number >= 1000:
result += "M"
number -= 1000
if number >= 900:
result += "CM"
number -= 900
if number >= 500:
result += "D"
number -= 500
if number >= 400:
result += "CD"
number -= 400
while number >= 100:
result += "C"
number -= 100
if number >= 90:
result += "XC"
number -= 90
if number >= 50:
result += "L"
number -= 50
if number >= 40:
result += "XL"
number -= 40
while number >= 10:
result += "X"
number -= 10
if number >= 9:
result += "IX"
number -= 9
if number >= 5:
result += "V"
number -= 5
if number >= 4:
result += "IV"
number -= 4
while number >= 1:
result += "I"
number -= 1
return result
|
| Listing 1 |
Leaving aside questions of type and range validation, this code works. We can find support for this claim through reasoning, review and running against the sample of test cases in Listing 2.
cases = [ # Decimal positions correspond to numerals [1, "I"], [10, "X"], [100, "C"], [1000, "M"], # Quinary intervals correspond to numerals [5, "V"], [50, "L"], [500, "D"], # Multiples of decimal numerals concatenate [2, "II"], [30, "XXX"], [200, "CC"], [3000, "MMM"], # Non-multiples of decimals concatenate in # descending magnitude [6, "VI"], [23, "XXIII"], [273, "CCLXXIII"], [1500, "MD"], # Numeral predecessors are subtractive [4, "IV"], [9, "IX"], [40, "XL"], [90, "XC"], [400, "CD"], # Subtractive predecessors concatenate [14, "XIV"], [42, "XLII"], [97, "XCVII"], [1999, "MCMXCIX"] ] failures = [ [number, expected, roman(number)] for number, expected in cases if expected != roman(number) ] assert failures == [], str(failures) |
| Listing 2 |
So, sure, the function works, but it ain’t pretty. It’s the kind of code only an enterprise programmer could love. Or, perhaps, a Pascal programmer: this control-flow–heavy approach was used in Pascal: User Manual and Report by Kathleen Jensen and Niklaus Wirth. Given that Pascal was often held up as a language from which and in which to learn good practice this might be considered ironic.
The code for the roman function is very procedural in that it is relentlessly imperative and control-flow oriented. Even as a procedural solution, however, it is not a particularly good one. It is repetitive, clumsy and lacking in abstraction.
If, however, we look at this code as a stepping stone rather than as an end state, it becomes an example and opportunity – especially in the presence of tests – rather than a counterexample and dead end. This latitude is perhaps a generosity we should extend to most code. Unless, like Romans chiselling words and numerals onto buildings, you are setting your code into stone, it may always be best to consider code a work in progress.
In the eyes of those who anxiously seek perfection, a work is never truly completed – a word that for them has no sense – but abandoned; and this abandonment, of the book to the fire or to the public, whether due to weariness or to a need to deliver it for publication, is a sort of accident, comparable to the letting-go of an idea that has become so tiring or annoying that one has lost all interest in it.
~ Paul Valéry
From duplication to unification
Recurrent structure is often a good starting point for seeing what can be abstracted. At first glance, the rhythmic stanza of a while followed by three if statements looks like a good fulcrum from which to lever a refactoring (Listing 3).
while number >= 1000: result += "M" number -= 1000 if number >= 900: result += "CM" number -= 900 if number >= 500: result += "D" number -= 500 if number >= 400: result += "CD" number -= 400 |
| Listing 3 |
The structure of this fragment for 1000, 900, 500 and 400 is repeated for 100, 90, 50 and 40 and then again for 10, 9, 5 and 4. But refactoring based on this recurrence misses a deeper duplication and, therefore, unification.
Consider, first, what is a while statement? It is a statement that, governed by a condition, executes zero to many times. What, then, is an if statement? It is a statement that, governed by a condition, executes zero times or once. Squinted at just right, an if can be considered a bounded case of a while.
Looking at the specific numbers and operations involved, we see the while-only code in Listing 4 is equivalent to the previous mix of while and if code.
while number >= 1000: result += "M" number -= 1000 while number >= 900: result += "CM" number -= 900 while number >= 500: result += "D" number -= 500 while number >= 400: result += "CD" number -= 400 |
| Listing 4 |
The newly minted while statements will execute zero times or once, just like their if antecedents. There is no change in behaviour, but there is a huge change in how we perceive the problem and the shape and nature of what we want to refactor.
We now have thirteen loops that look like
while number >= value:
result += letters
number -= value
What matters most to the solution is the series of threshold values and their corresponding letters. This is not a control-flow problem: it is a data problem. We need data structure, not control structure (see Listing 5).
def roman(number):
numerals = [
[1000, "M"], [900, "CM"],
[500, "D"], [400, "CD"],
[100, "C"], [90, "XC"],
[50, "L"], [40, "XL"],
[10, "X"], [9, "IX"],
[5, "V"], [4, "IV"],
[1, "I"]
]
result = ""
for divisor, letters in numerals:
result += (number // divisor) * letters
number %= divisor
return result
|
| Listing 5 |
This version still qualifies as procedural, but it is more declarative than the first version, which was strictly imperative.
Data-driven approaches separate data from the code that is driven by the data, with the effect of making both intent and structure clearer. Niklaus Wirth stated that Algorithms + Data Structures = Programs [Wikipedia-3], but algorithm and data structure are not necessarily equal partners. As Fred Brooks noted, in The Mythical Man Month under the heading ‘Representation Is the Essence of Programming’:
Sometimes the strategic breakthrough will be a new algorithm […]. Much more often, strategic breakthrough will come from redoing the representation of the data or tables. This is where the heart of the program lies. Show me your flowcharts and conceal your tables, and I shall continue to be mystified. Show me your tables, and I won’t usually need your flowcharts; they’ll be obvious.
We are more likely to code control flow directly than chart it, but that serves to highlight that while some things in the world of programming change, there is nothing new in letting the data do the talking. This family of approaches, from lookup tables to table-driven code, finds expression across many paradigms and contexts – the data-driven tests for roman already shown, for example – but is often overlooked. This way of thinking is either not taught fully and explicitly or, in the case of less capable languages like Pascal, cannot always be expressed conveniently.
Tables apart
There’s (a lot) more that we could do to explore the algorithmic space and paradigm shapes of the Roman numerals problem, such as transforming the loop into a fold operation (reduce in Python) or eliminating the arithmetic and expressing the solution using term rewriting (converting to unary and then using replace [Deigh17]), but for now we’ll leave the control flow in place so we can take off in a different direction to explore the organisation of the code elements.
Because the numerals table doesn’t change and is independent of the number parameter, we can implement invariant code motion to hoist it out of the function. (See Listing 6.)
numerals = [
[1000, "M"], [900, "CM"],
[500, "D"], [400, "CD"],
[100, "C"], [90, "XC"],
[50, "L"], [40, "XL"],
[10, "X"], [9, "IX"],
[5, "V"], [4, "IV"],
[1, "I"]
]
def roman(number):
result = ""
for divisor, letters in numerals:
result += (number // divisor) * letters
number %= divisor
return result
|
| Listing 6 |
We can add further distance to this separation by placing the definition of numerals into another source file, numerals.py (Listing 7), which leads to the code module being, well, just code. (See Listing 8.)
numerals = [ [1000, "M"], [900, "CM"], [500, "D"], [400, "CD"], [100, "C"], [90, "XC"], [50, "L"], [40, "XL"], [10, "X"], [9, "IX"], [5, "V"], [4, "IV"], [1, "I"] ] |
| Listing 7 |
from numerals import numerals
def roman(number):
result = ""
for divisor, letters in numerals:
result += (number // divisor) * letters
number %= divisor
return result
|
| Listing 8 |
Perhaps not for this particular problem, but this is an interesting decoupling because – as long as the data’s structure is consistent – it allows us to change the actual data independently of the algorithm. We are using the Python in numerals.py as a data language, which, in effect, makes numerals.py a native database. Another way of looking at the separation is that the code in roman.py implements an interpreter for the highly domain-specific data language of numerals.py.
On the dualism of data and code
This leads us to ponder – and not for either the first or the last time in the history of computer science – the distinction between code and data. We stumble across this question even in the simplest cases. How would you describe the refactoring transformations above? Many would describe them in terms of separating the data from the code. Does that mean, then, that numerals.py contains data but not code? It’s a valid Python module that initialises a variable to a list of string–integer pairs. Sounds like code. Nothing says an essential qualification for something to be considered code is the presence of control flow.
We use the word code freely, referring both to anything written in a programming language and, more specifically, to code (sic) whose primary concern is algorithm and operation rather than data structure and definition. Natural language is messy like that, filled with ambiguity, synecdoche and context dependency.
If we want to be more rigorous, we could say that we have separated the code into code that abstracts operation and code that abstracts data. In other words, we are saying that Programs = Code and, given that Algorithms + Data Structures = Programs, therefore Algorithms + Data Structures = Code. This can be convenient and clear way to frame our thinking and describe what we have done. We also need to recognise, however, that it is just that: it is a thinking tool, a way of looking at things and reasoning about them rather than necessarily a comment on the intrinsic nature of those things; it is a tool for description, a way of rendering abstract concepts more concretely into conversation.
If we confuse a point of view for the nature of things we will end up with a dichotomy that feels like Cartesian dualism. Just as Descartes claimed there were two distinct kinds of substance, physical and mental, we could end up claiming there are two distinct kinds of code – code that is data and code that is operation.
When we look to hardware, compilers or the foundations of computer science, such as Turing machines, we will not find clear support or a strict boundary for such separation. The indistinction runs deep. Although we have code and data segments in a process address, these enforce negotiable matters of convention and protection (e.g., the code or text segment is often read-only). Both code and data segments contain data, but the data in the code segment is intended to be understood through a filter of predefined expectations and an instruction set. On the other hand, it is also possible to treat data in the data segment as something to execute.
The fundamental conceit of the Lisp programming language is that everything can be represented and manipulated as lists, including code. The Lisp perspective can be summarised as Data Structures = Programs. For some languages, source code is data for a compiler, that in turn generates data for a machine – physical or virtual – to execute. For other languages, such as Python, source code is a string that can be interpreted and executed more directly. We can blur that code–data boundary explicitly in our example seen in Listing 9.
source = """[ [1000, "M"], [900, "CM"], [500, "D"], [400, "CD"], [100, "C"], [90, "XC"], [50, "L"], [40, "XL"], [10, "X"], [9, "IX"], [5, "V"], [4, "IV"], [1, "I"] ]""" numerals = eval(source) |
| Listing 9 |
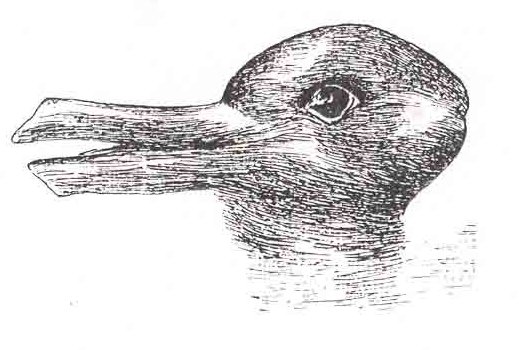
The dualism we are grappling with here is not the strict categorisation of things that are intrinsically separate, but the dualism of things that are innately bound together. A yin and yang of complementary perspectives that we are forcing into competition, but that exist in a cat state as easily resolved one way as the other. Which one we see or chose is a question of observation and of desire and of the moment rather than one of artefact (Figure 1).
|
The rabbit–duck (or duck–rabbit…) illusion.
Image from Wikimedia Commons [Wikimedia]. |
| Figure 1 |
The tables are turned
Instead of involving intermediate variables and conversions, we could simply replace numerals.py with a file that contains just the data expression, no statements (see Listing 10).
[ [1000, "M"], [900, "CM"], [500, "D"], [400, "CD"], [100, "C"], [90, "XC"], [50, "L"], [40, "XL"], [10, "X"], [9, "IX"], [5, "V"], [4, "IV"], [1, "I"] ] |
| Listing 10 |
Although a valid Python expression, this is no longer a useful Python module. The data is not bound to a variable that can be referenced elsewhere. It does, however, bear a striking resemblance to a more widely recognised data language: JSON (see Listing 11).
with open("numerals.json") as source:
numerals = eval(source.read())
def roman(number):
result = ""
for divisor, letters in numerals:
result += (number // divisor) * letters
number %= divisor
return result
|
| Listing 11 |
If you had wondered why I’d avoided using tuples and single-quoted strings in the code so far, you now have your answer: looked at the right way, JSON is almost a proper subset of Python. (If you hadn’t, no worries. As you were.) The relationship becomes closer and the observation truer if you replace the previous eval expression with the following:
eval(source.read(),
{"null": None, "false": False, "true": True})
Of course, this lets more through than just valid JSON, which may make you feel – justifiably – a little uncomfortable. We can more fully acknowledge and safeguard the transformation by replacing the permissive and general eval with something more constrained and specific:
from json import loads
with open("numerals.json") as source:
numerals = loads(source.read())
Configuration is code
Looking at the progression of code above, evolving from the first tabular version to the final JSON version, at what point in the transformation did the table stop being code and start becoming configuration?
This is, to some extent, a trick question, but that is also the point. We’re not done with dualism, ambiguity and perspective. The question serves to highlight a common blind spot and oversight: configuration is code. Treating configuration as disjoint from the concept of code steers us in the wrong direction. Treating it as something other often leads to it being treated as something lesser.
What, then, is configuration? It is a formal structure for specifying how some aspect of software should run. Sounds like code. It doesn’t matter whether configuration is defined in key–value pairs or a Turing-complete language, whether it uses an ad hoc proprietary binary format or a widely used and recognised text-based one, if a software system does not behave as expected, we consider it a problem. Whether that problem originated in a JSON payload, a registry setting, a database, an environment variable or the source code is not relevant: the software is seen as not working — there is a bug to be fixed.
The consequences of incorrect configuration range from the personal inconvenience of having your settings trashed when an app updates to the more costly failure of a rocket launch [Clark17]. Configuration is no less a detail than any other aspect of a software system. Its common second-class citizenship, however, causes it to be accorded less respect and visibility, leading to a high incidence of latent configuration errors [Xu] . If we consider it as code we are more likely to consider version control, testing, reviewing, design, validation, maintainability and other qualities and practices we normally confer on other parts of our codebase but may overlook for configuration.
Programming with perspective
Whether you find yourself exploring TDD with Roman numerals, playing with the Gilded Rose refactoring kata [Bache], casting an intricate set of constraints into code or trying to crack the code of a legacy logic tangle, inverting the problem with respect to data can you show you the problem and solution in ways you might not otherwise see if you only view it from the journey of control flow.
That said, although data-driven and table-lookup approaches are unreasonably effective, the message here is not that a data-centred approach is unconditionally the path of choice regardless of your situation. It is all too easy to jump from one world view to another without properly learning the lessons of either or the journey in between. If the default way that code is cast is in terms of control flow, however, viewing program structure through the prism of data structure often reveals an extended spectrum of complexity-reducing possibilities.
We should be wary of any quest for the One True™ paradigm or a silver bullet solution, and cautious of such exclusive attachment. As Émile-Auguste Chartier cautions us:
Nothing is more dangerous than an idea when you have only one idea.
The value of paradigms, perspectives and points of view is in their multiplicity. Sometimes one offers a better frame for understanding or creation than another — and in some contexts it might do so consistently. Sometimes habit leads us to get stuck with one and neglect others. Sometimes, like binocular vision, we need more than one to make sense of a situation or to unlock a solution.
References
[Bache] Emily Bache ‘Starting code for the GildedRose Refactoring Kata in many programming languages’ available from https://github.com/emilybache/GildedRose-Refactoring-Kata
[Clark17] Stephen Clark (2017) ‘Russian official blames Nov. 28 launch failure on botched software programming’ available from https://spaceflightnow.com/2017/12/30/russian-official-blames-nov-28-launch-failure-on-botched-software-programming/
[Deigh17] Teedy Deigh (2017) ‘All About the Base’ in Overload 138, April 2017, available from: https://accu.org/journals/overload/25/138/deigh_2364/
[Kruchten95] Philippe Kruchten (1995) ‘The 4+1 View Model of Architecture’ published in IEEE Software 12(6):45-50, available from https://www.researchgate.net/publication/220018231_The_41_View_Model_of_Architecture
[MathsIsFun] Roman Numerals: https://www.mathsisfun.com/roman-numerals.html
[ODP] Reference Model of Open Distributed Processing (RM-ODP): http://www.rm-odp.net/
[Wikimedia] File: Duck-Rabbit illusion.jpg: https://commons.wikimedia.org/wiki/File:Duck-Rabbit_illusion.jpg
][Wikipedia-1] Hindu–Arabic numeral system: https://en.wikipedia.org/wiki/Hindu%E2%80%93Arabic_numeral_system
[Wikipedia-2] Kata (programming): https://en.wikipedia.org/wiki/Kata_(programming)
[Wikipedia-3] Algorithms + Data Structures = Programs: https://en.wikipedia.org/wiki/Algorithms_%2B_Data_Structures_%3D_Programs
[Wiktionary] Sign-value notation: https://en.wiktionary.org/wiki/sign-value_notation
[WordFriday] Bi-quinary coded decimal (2014): https://www.facebook.com/WordFriday/posts/725954844159142/
[Xu] Tianyin Xu, Xinxin Jin, Peng Huang, and Yuanyuan Zhou, University of California, San Diego; Shan Lu, University of Chicago; Long Jin, University of California, San Diego; Shankar Pasupathy, NetApp, Inc. ‘Early Detection of Configuration Errors to Reduce Failure Damage’ available from https://www.usenix.org/conference/osdi16/technical-sessions/presentation/xu
is a consultant, speaker, writer and trainer. His interests include programming languages, software architecture and programming practices. Kevlin loves to help and inspire others, share ideas and ask questions. He is co-author of A Pattern Language for Distributed Computing and On Patterns and Pattern Languages, editor of 97 Things Every Programmer Should Know and co-editor of 97 Things Every Java Programmer Should Know.


{kind=link}