








Parallelism is powerful. Lucian Radu Teodorescu explains the new C++ proposal for managing asynchronous execution on generic execution contexts.
In software engineering, it’s often the case that a change of perspective can dramatically modify the perceived usefulness and complexity of a given piece of code. Probably one of the most famous examples in the C++ world is Sean Parent’s rotate algorithm [Parent13]; once you realise that a complex loop is essentially a rotate operation, you can simplify how you write the code a lot, but, more importantly, also how you reason about the code.
I believe that most of us have had several of these “Aha!” moments during our programming careers, which significantly improved our understanding of some programming problems. Some of us might remember the joy provoked by the understanding of pointers, backtracking, dynamic programming, graph traversal, etc. We probably often don’t pay attention to these moments, and they are constantly happening. Sometimes the trigger is learning a new technology, sometimes it is learning a new trick, and sometimes it is just a clear explanation from a colleague.
But, regardless of the trigger for these moments, oftentimes the result is that the change of perspective brought a positive improvement in understanding. The problem does not change, but the way we approach it is (fundamentally) different. And sometimes the end results are remarkable.
This article is about such a perspective change. In fact, it’s about two separate perspective changes: one coming from the C++ standard committee, as they revised and reworded the executors proposal, and one from my side, looking at the proposal in an entirely different way.
However, before diving into this perspective change, I owe the readers an apology.
Errata
In my last article, ‘C++ Executors: the Good, the Bad, and Some Examples’ [Teodorescu21], I made one major mistake. While trying to pick out some pros and cons of the proposal of the initial set of algorithms ([P1897R3]), I claimed that the proposed executors do not have a monadic bind operation defined. This is fundamentally wrong. I failed to realise that the proposal defines the let_value operation, which is precisely the monadic bind. I was confused about the description of the operation and failed to realise that this is the monadic bind I was looking for.
The let_value operation receives two parameters: a sender and an invocable, and returns another sender. When the whole computation runs, the value resulting from running the input sender is passed to the given invocable. This invocable is then returning a sender, possibly yielding a different value type. There you go: this is just the monadic bind.
I hope the readers will excuse me for this error.
A new proposal, a new perspective
This year, the C++ standard committee dropped [P0443R14] and related proposals, and combined all the important pieces into a new proposal: P2300: std::execution [P2300R1].
The core of the proposal is the same. The proposal envisions that senders and receivers are the basis for expressing asynchronous execution, concurrency, and parallelism in future C++ programs. While the core remains the same, there are some fundamental changes to the new [P2300R1] proposal.
I would categorise these changes into two groups: simplification of the concepts and simplified presentation. Let’s analyse them individually.
Simplification of concepts
The first major simplification is the dropping of the concept of executor completely, along with any of the related functionalities. The new proposal argues that executor concepts should be replaced by schedulers (and senders). The core responsibility is the same for both, and it makes sense to drop one of them. And schedulers have the advantage over executors in that they also have completion notifications; one can get notified when a certain work is completed (whether successfully, with an error or cancelled) with schedulers, but with executors, the same job is much more complex. Thus, schedulers have the advantage here.
The idea of an executor is elementary: an executor executes work. Schedulers are not as easy to describe; they can be described by schedulers represent execution contexts, or schedulers represent strategies for scheduling work on execution contexts. This difference of perceived complexity is somewhat subjective, but I argue that the idea of executing work is easier to understand than scheduling work for execution.
However, this complexity is just at the surface. One can easily transform a scheduler into an executor. In fact, the paper proposes an algorithm void execute(scheduler auto sched, invocable auto work) that practically makes the scheduler behave like an executor. To make things clearer, here is a possible implementation (a bit simplistic, but it works):
void execute(scheduler auto sched,
invocable auto work) {
start_detached( schedule(sched) | then(work) );
}
This function calls three algorithms defined by [P2300R1]. Calling schedule on a scheduler object will return a sender that would simply send an impulse and no value to its receiver. The then algorithm takes the impulse coming from the scheduler and calls the work. This ensures that the work will be executed whenever the scheduler schedules the work, and on whatever execution context is defined in the scheduler. The then algorithm also returns a sender. The whole thing is started by start_detached, which ensures that the entire composition will start to be executed.
The second change that I would call major is the removal of the submit operation and, with that, the cleaning of possible operations on the main concepts. The old submit() operation can be substituted by the more flexible connect()/start() pair as shown in this (simplified) definition:
void submit(sender auto s, receiver auto recv) {
start(connect(std::move(s), std::move(recv)));
}
This removal makes the important concepts and operations between them easier to understand:
- schedulers are strategies for scheduling work on the execution context
- one can call
schedule()on a scheduler to obtain a sender that just sends an impulse on the right execution context
- one can call
- senders describe work to be done
- one can call
connect()on a sender and a corresponding receiver to obtain an operation state object
- one can call
- receivers are completion notifications and serve as glue between senders
- senders will call one of
set_value,set_doneorset_erroron them
- senders will call one of
- operation states represent actual work to be done1
- one can call
start()on an operation state to actually start the work
- one can call
The paper envisions that end users will only use schedulers and senders, while receivers and operation states are more of a concern to the library implementers. But, more on that later.
There are more changes that [P2300R1] makes over [P0443R14] and related papers. The new proposal adds more algorithms to make it simpler for users to use this proposal in various contexts, allows implementers to provide more specialised algorithms, removes the need for properties (replacing them with scheduler queries, which are much easier to understand for regular programmers), etc. Such changes make the whole proposal more approachable by typical C++ programmers. We won’t be diving into these now. I highly encourage the reader to take a look at the proposal…
Simplified presentation
One pleasant surprise of the new proposal [P2300R1] is that it can be easily read, without being a C++ expert. The new proposal is organised in such a way that it can be read by both users and library creators; it’s not quite for beginners, but still, it’s accessible to a larger audience. Again, I urge the reader to take a look at the [P2300R1] proposal to check this.
One of the first things to notice is that the new proposal starts with clear motivation, a set of guiding priorities and some well-explained examples. These will allow the typical reader to understand much more easily the problem that the proposal tries to solve. Thus, by this new arrangement of the content, the authors make the whole proposal seem less complex.
But probably the biggest perspective shift that reduces the complexity is the breakdown of the proposal design into user side and implementer side. In other words, the authors clearly delimit between the things that most users will care about, and the things that mostly the implementers will care about. This translates into a great simplification for most users.
In terms of concepts, users will care about schedulers and senders. Schedulers, as mentioned above, describe execution contexts. The only thing that the user can do with them is to obtain a sender. The current proposal allows this only by using the schedule() algorithm; in the future, there might be other ways to create senders.
Senders, on the other hand, can be manipulated in multiple ways using sender algorithms. Here, the paper also makes it easier for users to understand the proposed functionality by breaking these sender algorithms into three categories:
- sender factories (
schedule(),just()andtransfer_just()) - sender adaptors (
transfer(),then(),upon_*(),let_*(),on(),into_variant(),bulk(),split(),when_all(),transfer_when_all()andensure_started()) - sender consumers (
start_detached()andsync_wait())
Now, even without knowing what these algorithms do, one can intuitively figure out the rough idea behind them. And this helps a lot in improving understandability of the whole proposal.
Arranging user-facing concepts like this is a change of perspective that makes the proposal seem less complex.
Only after presenting all the user-facing concepts does the paper go into describing the design of the concepts and algorithms needed for the implementer. The average user will not care about this. In this section, the paper describes the design of the receivers and of the operation states, how the senders can be customised, and the design decisions that make senders and receivers be performant in many different contexts.
What is commonly known as the proposal of senders and receivers, now splits the senders from receivers, making them part of different sets of concerns. It’s just a change of perspective, but this change makes the proposal look simpler.
Key insight: it’s all about computations
The second major change of perspective presented in this article is my own change of perspective. Since the last article [Teodorescu21], I have had an Aha! moment that made me realise that one can look at schedulers, senders and receivers in a simpler way.
Naming
The main problem that I had with the previous proposal was that the names sender and receiver are extremely abstract. In fact, one can apply the sender/receiver terminology to function composition, single-threaded algorithms, processes, Unix pipes, architectural components, and a multitude of other concepts in software engineering. Moreover, in the concurrency world, there are many types of useful tasks in which we are not sending and receiving any important data; the sending and the receiving part is not essential, the execution of the task is.
The change of perspective that I’m proposing is the following:
- let’s think of senders as async computations
- let’s think of receivers as async notification handlers
Because asynchronicity is implied in this context, I’ll drop the term async and keep just computations and notification handlers. I argue that it’s easier to explain to users the concepts described in [P2300R1] by using computations and notification handlers instead of senders and receivers.
One can easily think of computations as just description of work to be executed in one or multiple execution contexts. Schedulers are then the objects that schedule computations: when and where these should start executing. Receivers, if one needs to use them, are the handlers that get notified about the completion of computations. Doesn’t sound that complicated.
To make things clearer, I’ll make the distinction between computation and computation parts. Let’s look at one simple example:
auto c1 = schedule(my_scheduler); auto c2 = then(c1, some_work_fun); auto c3 = then(c2, some_other_work_fun); start_detached(c3);
We define three computations: c1, c2, and c3. The first computation is a part of the second computation, which, in turn, is a part of the third computation. When we refer to a computation, we refer both to the algorithm that we are using to define it (along with its parameters) and to the base sender that the algorithm might take. Thus, the c3 computation also includes c2. However, a computation_part is only the algorithm invocation, without including the base computation.
While a computation can be recursively defined, a computation part refers only to a narrow description of an operation that needs to be executed as a part of a chain.
Figure 1 tries to illustrate the recursion of computations. c3 defines the entire computation, and it consists of 3 parts (colored differently). c3 recursively contains c2 which in turn contains c1.
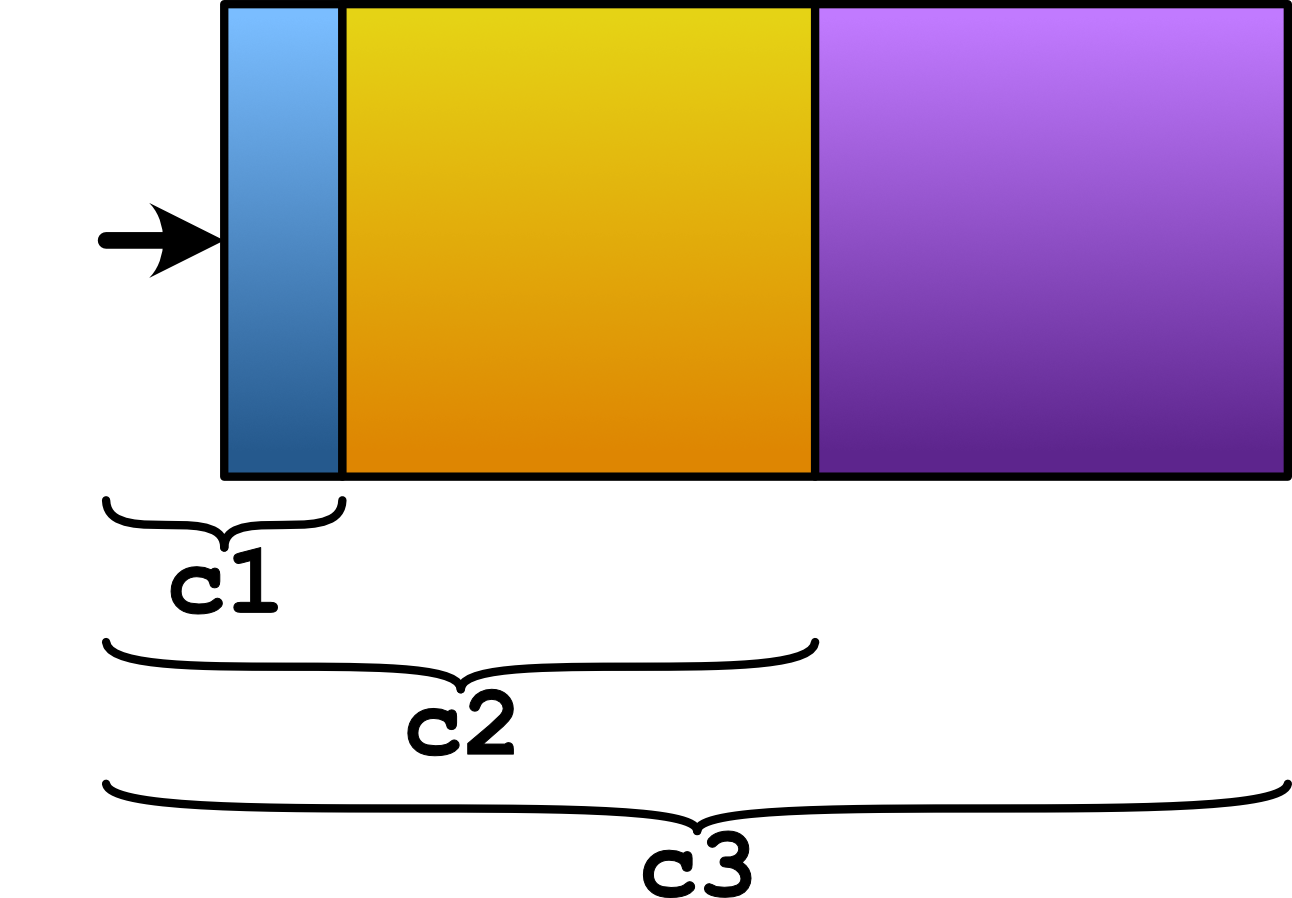 |
| Figure 1 |
Computations and tasks
In [Teodorescu20], we defined a task to be an independent unit of work. That is, the minimal amount of work that can be executed in one thread of execution, in such a way that it doesn’t conflict with other active tasks currently executing. Leaving the independent part aside for a moment, let’s compare tasks and computations with from the amount of work perspective.
Having [P2300R1] in mind, computations can be created at different levels:
- sub-unit computations; where multiple computations are chained together to form a unit of work (typically run on a single thread)
- unit computations; where a computation is roughly equivalent to a task
- multiple unit computations; where the computation corresponds to more than one task, possible executed on different threads.
The code in the section above showed an example of sub-unit computations. We will show, however, an example containing the two other categories in Listing 1.
// unit
sender auto start = schedule(my_scheduler);
sender auto c2 = start | then(save_log_to_disk);
start_detached(c2);
// more than one unit
sender auto start2 = split(schedule(my_scheduler));
sender auto c3 = when_all(
then(star2, [] { do_first_work(); }),
then(star2, [] { do_second_work(); })
);
start_detached(c3);
|
| Listing 1 |
It’s interesting to notice that, even in this example, sub-unit computations are defined. In fact, most of the time, the framework forces the user to employ sub-unit computations. Some of them are stored in named variables, and some of them are just temporaries. In this example, both start and start2 variables represent sub-unit computations.
The variables c1 and c2 represent tasks, so we can say that they are units of work.
In the second part of the example, we’ve shown a computation that spawns two tasks and ensure they are both executed. In this sense, c3 describes more work than a task can.
This example is illustrated in Figure 2. c2 looks just like a task, while c3 describes two independent tasks, plus the initial split operation and the final join operation. This suggests that computations can represent higher level patterns of concurrency.
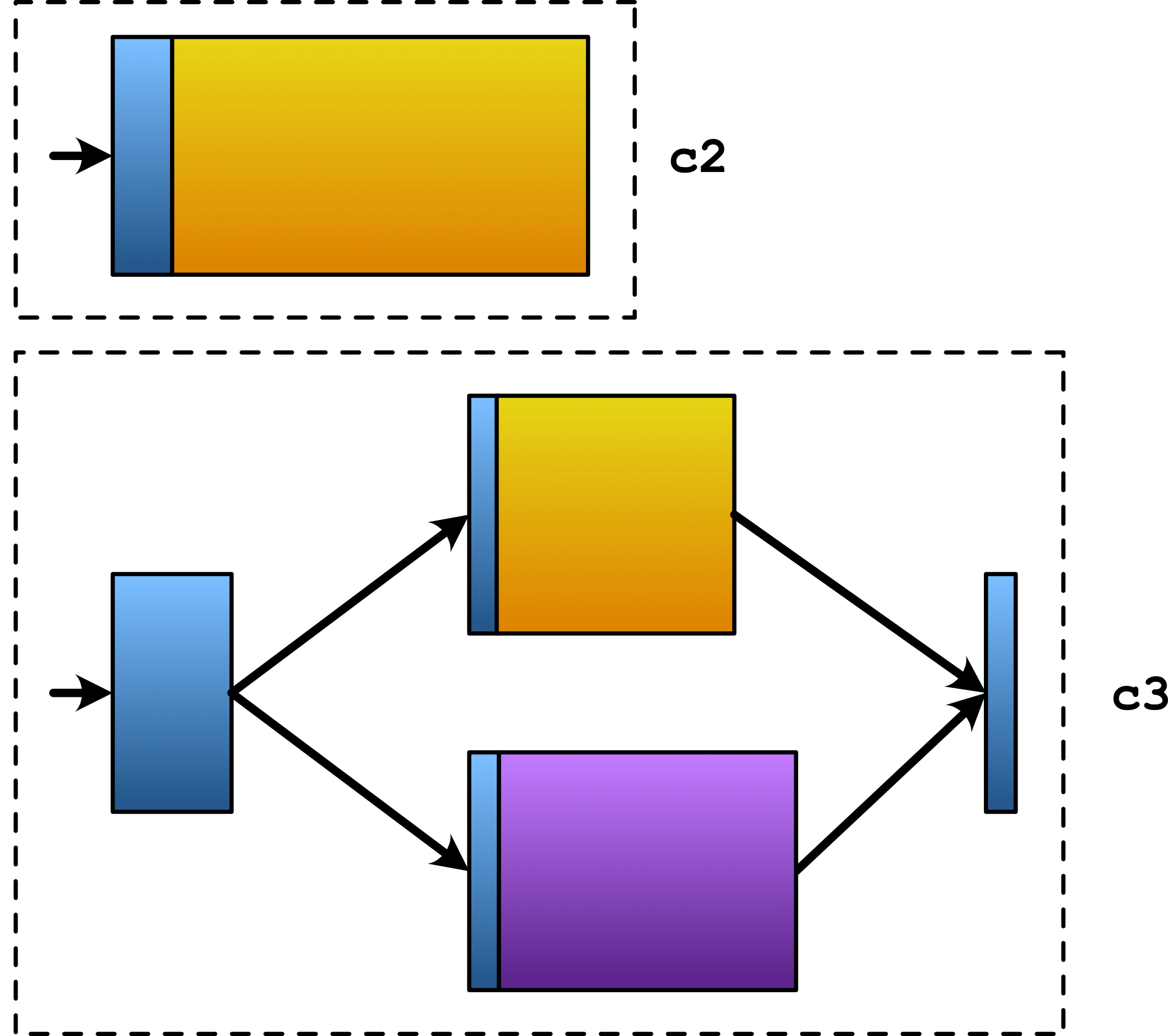 |
| Figure 2 |
In order for a computation to become greater than a unit of work, one has to call some algorithms that can move work from one thread to another. Example of such algorithms are split, transfer or bulk. We can easily identify these cases just by code inspection.
On the other hand, the distinction between sub-unit and unit computation may not always be clear. The same computation can be both a sub-unit and a unit computation in different contexts; the user of the computation decides whether it is a part of a bigger unit computation or it is spawned into a task.
The bottom line is that these computations (again, they are called senders in [P2300R1]) can have different sizes, sometimes much bigger than tasks. This has two important consequences:
- As computations can be equivalent with tasks, everything that can be modelled with tasks can also be modelled with computations.
- Computations can be used to express large parts of the concurrent applications.
The first consequence is crucial. We proved in [Teodorescu20] that every concurrent system can be described with tasks, and we don’t need mutexes or any other low-level synchronisation primitives (except in the task framework itself). With this consequence in mind, we can apply the same conclusion with a system based on computations (or senders): all concurrent problems can be expressed with just computations, without needing synchronisation primitives in user-code. We can use computations as a global solution to concurrency.
This is where the independent part in the definition of a task is important. We assume that the breakdown of work between computations is done in such a way that two computations that can be run in parallel will not produce unwanted race conditions.
If the first consequence allows us to prove the existence of a general algorithm for handling the concurrency algorithm (something that we won’t do in this article), the second consequence allows us to easily build complex concurrent applications. Let’s quickly dive into this.
Composability of computations
As we’ve seen above, computations are built on top of each other, starting from small primitives and building up. This is especially visible when we use the pipe operator (see above example). What is on the left of the pipe operator (i.e., |) are computations, but also the result of the pipe computations are computations. That is, smaller computations are composed into bigger computations. That is, computations are highly composable.
The examples in the proposal are, of course, small; the authors couldn’t have spent most of the papers discussing a large example. We won’t do that here either, but we will try to contemplate how such an example might look.
Let’s assume that we want to build a web server, with functionality similar to Google Maps. One needs to implement operations for downloading map data, for searching the map and for routing through the map, plus other less-visible operations (e.g., getting data for points-of-interest, downloading pictures, searching similar points of interests, etc.). Some operations might be bigger (e.g., calculating routes) and some might be smaller (e.g., downloading data).
If we ignore the concerns related to network communication, security and data packaging, the application needs to have some request handlers that, given some inputs, will generate the right outputs to be sent to the user. Let’s focus on this core part. Each type of request will have a corresponding handler. These handlers can vary in size for anything between small and big. But, we can express any of these handlers as one computation. Each of these computations can be then made by joining in multiple smaller computations.
A computation that will implement the routing algorithm will probably be broken down into computations that will perform a general analysis of the situation, read the corresponding map data into memory, perform a graph routing algorithm to find the best path, compute the properties of the best route found, gather all the data that needs to be sent down to the client, etc. All of these can be implemented again in terms of computation. Moreover, they can be executed on multiple threads of execution inside the same server, or can be distributed across multiple servers. We can represent all of this using computations.
For example, Listing 2 shows how one can encode the part that reads the data needed for such a request.
sender auto read_data_computation(in_data_t data) {
return just(data) | then(break_into_tiles)
| let_value(load_tiles_async);
}
sender auto load_tiles_async(tiles_t& tiles) {
size_t num_tiles = tiles.count();
return bulk(num_tiles, do_read_tile);
}
void do_read_tile(size_t tile_idx, tiles_t& tiles)
{...}
|
| Listing 2 |
Some brief explanations for this example:
- starting from the data received as argument,
read_data_computation()will first break the data into tiles and then attempt to load the tiles - the loading of the tiles is done in parallel by using the
bulkalgorithm; we divide the work to be done into smaller chunks, one pertile, callingdo_read_tileto read atile’s worth of data; load_tiles_asyncreturns a computation/sender; the way to integrate it into the upper level function is to use the monadic bind; this is done by using thelet_valuealgorithm; the reader hopefully sees why I had the urge to show an example oflet_value
Hopefully, you can understand the main idea behind our sketch example. We can compose computations into more and more complex computations, until we represent large chunks of the application as one bigger computation. This is extremely powerful.
Now, the point of this exercise was to show you that we can approach complex concurrency problems from a top-down perspective, and we’ve encapsulated the concurrency concerns into computations.
Applying this technique, we can have a structured approached to concurrency. We can easily define the concurrency structure of our programs, and we can make it as visible as any other major architectural structure. Here, when I say structured concurrency, I’m only referring to the high-level concerns of what it means to have a structured approach; please see Eric Niebler’s blog post on Asynchronous Stacks and Scopes [Niebler21] for a discussion of structured concurrency focusing on lexical scopes (what I would call the low-levels of structured programming).
An analogy with iterators
We’ve seen that computations and the corresponding algorithms are powerful mechanisms that:
- allow us to build any concurrent application
- allow us to build complex concurrent applications by composing simpler functionalities
This is excellent. But we still don’t have a good answer to whether the proposed abstractions are too complex. The perceived complexity of a software system is hard to define, and probably complexity of abstractions are even harder to define, so I don’t have a definitive answer here. Instead, I’ll try to provide a few hints.
Probably the best way to shed some light into this matter is an excellent analogy I’ve heard recently: senders/receivers are like iterators. I think this really captures the essence of the problem.
Coming from other programming languages, it may seem that iterators are too complex. However, they are proven to be the right abstraction to separate containers from algorithms. Moreover, C++ programmers are accustomed to iterators, and they don’t consider it as an overly complex feature.
Yes, it is probably easier to write my_vector.sort() than using iterators, but with C++20 we can express the same thing as std::ranges::sort(my_vector). It’s not bad at all.
But, even if we didn’t have ranges, the advantages of having iterators far outweighs the complexity costs that we are paying.
Let’s enumerate some of the benefits that the [P2300R1] proposal brings us:
- ability to represent all computations (from simple ones to complex ones)
- ability to represent computations that have inner parts that can be executed on different execution contexts (e.g., different threads, different computation units, different machines)
- can use computations to solve all concurrency problems (without using synchronisation primitives in the user code)
- composability
- proper error handling and cancellation support
- no memory allocations needed to compose basic computations
- no blocking waits needed to implement most of the algorithms
- allows flexibility in specialising algorithms, thus allowing implementors to create highly efficient implementations
- ability to interoperate with coroutines
All these put together seem to suggest that [P2300R1] brings the right abstractions in the C++ world. We can build correct and efficient applications with them. The standard committee seemed to hit the sweet spot with the abstraction level of senders and receivers. Not too low, so that it would be extremely hard for users to build concurrent applications, and not so high that we lose efficiency.
Raw tasks and executors might be a bit higher level or a bit easier to use. But they do not provide all the benefits that this proposal does; for example, error handling and achieving no memory allocations for composing computations is harder to obtain with raw tasks.
Yes, tasks and executors might be simpler on the surface, but senders/receivers have more advantages. Just like iterators are better than the apparently simpler algorithms-as-methods approach.
And, probably just like with iterators, one of the biggest challenges in the coming years for the C++ community is to find ways to teach computations to new programmers. This is something that may not be as easy as it sounds. But we must embark full speed on this endeavour.
A final perspective
During the course of this article, we showed that changing the perspective on senders and receivers, while maintaining the same core ideas, can result in a reduction of complexity. We argued that these abstractions will allow us to solve, in general, all concurrency problems, without needing blocking synchronisation in user code, and also the composability of computations allows us to easily represent with them any part of the system. Eventually, we made an analogy between these computations and iterators.
Although we might have some challenges teaching the new model, the end result is probably worth it. If everything goes well, we would have a good solution to concurrency. We hope to fix a concurrency model that has plagued the software industry for decades.
But is this the final perspective we will have on senders/receivers, computations or concurrency? Most probably not. History teaches us that we often come up with new perspectives that make old models look more appealing without changing the core concepts. Software engineering is a discipline of knowledge acquisition (see, for example, Kevlin’s brilliant presentation [Henney19]), so, changing the perspective (into a better one) is probably the best weapon to tame complexity.
Perspective change is something that happens a lot to me as well. And it’s not just happening to me out of the blue, it’s something that I constantly work towards: I constantly strive to refine my assumptions and thus my perspectives. Thus, I know already that this is not going to be my final perspective; it’s a better perspective, which will be someday superseded by yet another perspective.
I do not write articles to show I know something, but because in the process of laying down arguments my understanding becomes better; in fact, I can’t remember a single article that I have written for which I fully knew the conclusions beforehand. And, of course, I write because I believe that the readers too can benefit from this process. Hopefully, they can forgive me for the lack of definite solutions.
References
[Henney19] Kevlin Henney, ‘What Do You Mean?’, ACCU 2019, https://www.youtube.com/watch?v=ndnvOElnyUg
[Niebler21] Eric Niebler, ‘Asynchronous Stacks and Scopes’, 2021, https://ericniebler.com/2021/08/29/asynchronous-stacks-and-scopes/
[P0443R14] Jared Hoberock et al., ‘P0443R14: A Unified Executors Proposal for C++’, http://www.open-std.org/jtc1/sc22/wg21/docs/papers/2020/p0443r14.html
[P1897R3] Lee Howes, ‘P1897R3: Towards C++23 executors: A proposal for an initial set of algorithms’, http://www.open-std.org/jtc1/sc22/wg21/docs/papers/2020/p1897r3.html
[P2300R1] Michał Dominiak, Lewis Baker, Lee Howes, Kirk Shoop, Michael Garland, Eric Niebler, Bryce Adelstein Lelbach, ‘P2300R1: std::execution’, http://www.open-std.org/jtc1/sc22/wg21/docs/papers/2021/p2300r1.html
[Parent13] Sean Parent, C++ Seasoning, GoingNative, 2013, https://www.youtube.com/watch?v=W2tWOdzgXHA
[Teodorescu20] Lucian Radu Teodorescu, ‘The Global Lockdown of Locks’, Overload 158, August 2020
[Teodorescu21] Lucian Radu Teodorescu, ‘C++ Executors: the Good, the Bad, and Some Examples’, Overload 164, August 2021
Footnote
- We said that senders describe work, and operation state objects represent actual work. While senders are just pieces of work that need to be glued with receivers, the operation states represent these glued pieces of work. Starting an operation state will execute work, whereas we cannot simply start directly one sender.
has a PhD in programming languages and is a Software Architect at Garmin. He likes challenges; and understanding the essence of things (if there is one) constitutes the biggest challenge of all.

