








2022 has seen many languages created to rival C++. Lucian Radu Teodorescu reports on the current state of the art.
C++ is a peculiar programming language. It is one of the most used programming languages, and yet it is one of the most criticised. According to TIOBE index [TIOBE22], for 30 years, C++ has been in the top 4 programming languages (using a 12-month average). See also Figure 1 (the TIOBE Programming Community Index for October 2022) for language trends in the past 20 years.
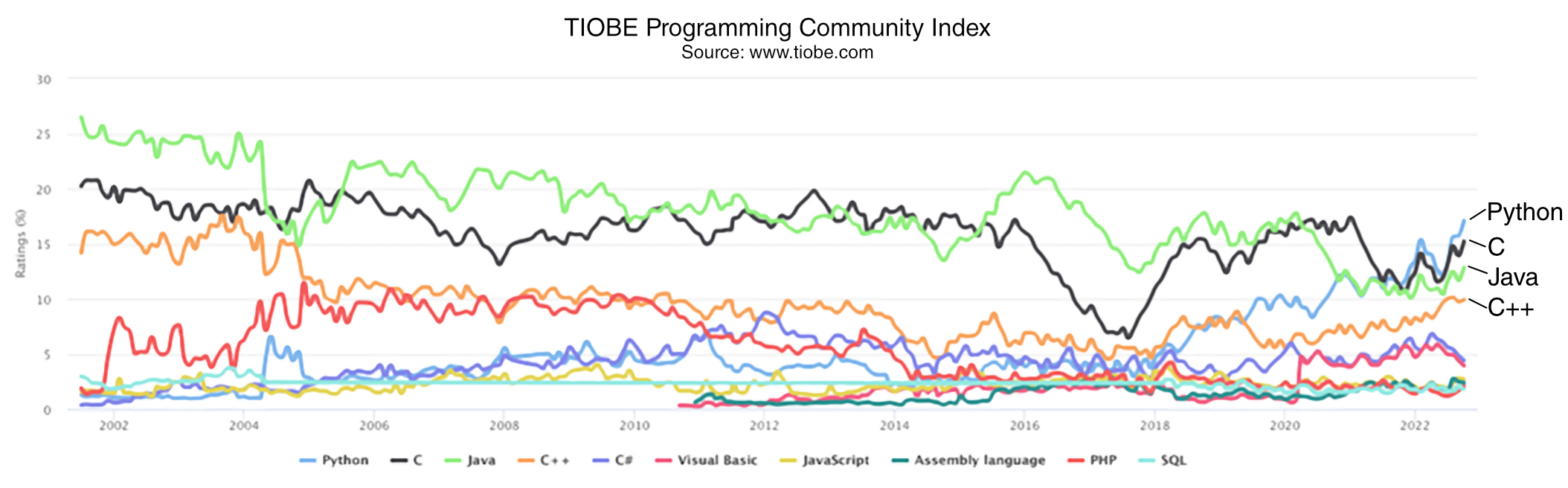 |
| Figure 1 |
For a language that has existed for almost 40 years, to be constantly in the list of top programming languages is a great achievement. It must be a language that is loved by its users. Well, paradoxically, that is not true. C++ is one of the most criticised languages. Personally, I couldn’t find any C++ programmer who argues that C++ is a beautiful language. Virtually everyone complains that the language is too big, too complex, with features that should be killed, with too many features, and, conversely, with not enough features. Over-generalising, C++ can be seen as a random collection of features without a clear, cohesive story.
Some of the most notable criticisms can be found on the C++ programming language Wikipedia page [Wikipedia]. While defending the language, Bjarne Stroustrup argues that “within C++, there is a much smaller and cleaner language struggling to get out” [Stroustrup94]. This quote is still in widespread use today, after 28 years. While this is meant to be defending C++, if we analyse it carefully, we realise that it’s also an implicit criticism: C++ still hasn’t become that smaller and cleaner language that people expect it to be. It may simply mean that this smaller and cleaner language is just a mirage.
So, the main question is: How can we obtain a better language that is simpler and cleaner than the current C++, and occupies the same space (system programming language) as C++? What does a C++ successor language look like?
And, while there have been some attempts to answer this question in the past, 2022 was the only year in which three possible successor languages were announced, all in keynote talks at major C++ conferences.
First, we have Val announced at C++ Now by Dave Abrahams and Dimitri Racordon [Abrahams22a, Abrahams22b, Val]. At the core of Val there is the idea that one can build safe and efficient programs using mutable value semantics [Racordon22a]
Two months later, at CppNorth, the Carbon language was announced by Chandler Carruth [Carruth22, Carbon]. The Carbon language tries to solve several aspects of C++: technical debt accumulated over decades, the prioritisation of backwards compatibility and the C++ evolution process.
Another two months after that, at CppCon, Herb Sutter announces CppFront, as a possible successor of C++ [Sutter22]. His main goal was to “bring C++ itself forward and double down on C++” and prevent users from migrating to other languages. The declared aims are to make C++ 50× times safer and 10× simpler.
This article tries to provide a critical perspective on these three languages. I’m not doing this because I think that they can’t be C++ successors; quite the opposite, I’m trying to lay out the problems that these languages need to solve before hoping to claim C++’s place. While I do have some personal biases, I’ll try my best to be objective in my analysis.
Previous attempts
The D programming language was created by Walter Bright and appeared in 2001; later in 2007, Andrei Alexandrescu joined the design and development effort. This language was supposed to learn from C++’s mistakes and be its successor. It promises the same level of efficiency but adds a ton of new features and simplifies some of the more complex parts of C++. The D homepage advertises D as a language in which one can “write fast, read fast, and run fast”.
D had attracted some commercial users, but it’s safe to say that it did not reach the status of an important programming language. While Andrei is one of my long-time heroes and I have a considerable respect for Walter, I mainly viewed D as a large collection of language features, loosely tied together. It feels to me that the language lacks a clear foundation that would give cohesiveness to all the features.
The Go programming language was introduced in 2009 by Google; version 1.0 was released in 2012. The goal of this language is to allow programmers to “build fast, reliable, and efficient software at scale”. The designers of the Go language disliked C++, so, as a consequence, Go seems more like an evolution of C than an evolution of C++. Go only added generics in 2022, and still lacks widely used features like exception handling.
Go is a language that implies the presence of garbage collection; this makes numerous C++ users consider it inappropriate for system programming. While Go can be called a successful programming language (number 11th in TIOBE Index [TIOBE22]), its success is mainly in the cloud business. Despite its relative success, it can’t be called a C++ successor.
Rust is a programming language developed at Mozilla, announced in 2010, with the first version released in 2015. Rust focuses on reliable (memory and thread safety) and efficient software. The Rust language model is based around the so-called borrow checker, which tracks the lifetime of all the objects; thus, it can detect safety errors at compile-time and does not require the use of a garbage collector.
Rust, although not as popular as Go ([TIOBE22]), seems to be considered a good replacement for C++. The problem is that there is no clear/clean/universal way to interface between Rust and C++; this makes C++ programmers that want to move to Rust experience an abrupt migration.
Val
Dave Abrahams and Dimitri Racordon announced Val at C++ Now 2022 [Abrahams22a, Abrahams22b] in a talk called ‘A Future of Value Semantics and Generic Programming’. They did not claim that Val might be a C++ successor language, but based on the title of the talk and the surrounding context (keynote at a major C++ conference) people inferred that Val might be one. Dave and Dimitri gave two more talks at CppCon 2022 that strengthened this position ([Abrahams22c, Racordon22b]).
Val positions itself with the following aims [Val]:
- Fast by definition
- Safe by default
- Simple
- Interoperable with C++
Val targets the audiences of C++, Rust and Swift languages with these goals. It aims to achieve the performance of C++ but guarantees safety in a simpler way than Rust does it. In terms of performance, Val aims to reduce the amount of object copying and memory allocations needed for writing safe software. In terms of safety, all constructs in Val are guaranteed to be safe, unless the user explicitly asks for extra control (marking portions of the code as unsafe). The simplicity of the language mainly comes from its strong Swift influence, which is usually considered to be a simple-to-use language.
Many programming languages don’t necessarily have a core idea that goes through all its features and acts like a catalyst for the language; this creates the impression that those languages lack coherence. This cannot be said about Val. This language stands out as having a model to programmatically eliminate safety issues: it’s called Mutable Value Semantics [Racordon22a]. But, before we get there, let’s explore the main problem that it solves.
C++ is inherently unsafe
It all starts with the observation that, in the presence of mutation, reference semantics can lead to unsafe programs. Because reference semantics allow the creation of complex dependency graphs, mutation cannot guarantee that safety is preserved across the entire graph. If, for example, a function operates on two objects and changes one of them, there is no guarantee that the other object doesn’t change in a completely unexpected way. This creates a problem in both single-threaded and multi-threaded environments. Moreover, there isn’t a systematic way for us to validate the consequences of a mutation without deeply inspecting all the code that is potentially impacted. This simply breaks the core ideas of structured programming.
Take the following C++ code snippet:
void append_vec(vector<int>& dest,
const vector<int>& src) {
for ( auto x: src )
dest.push_back(x);
}
Ignoring the inefficiency in the implementation, the code has a serious safety issue. And, this issue cannot be easily seen if we look at this code alone; we have to look at the surrounding code as well. If the caller of this function provides the same vector both as source and as destination parameter, then this leads to undefined behaviour.
To ensure proper semantics for functions like this, we need an independence guarantee: we need to ensure that the objects we interact with (and we write to at least one of them) are not identical. This cannot be properly enforced in the language; thus we are inherently in unsafe territory.
I would like to point out that the issue here is more complicated than it looks. If both arguments of a function are const references (i.e., we are not changing anything in them), then there is no issue. The problem only arises when we have mutation.
Swift solves this problem by using the copy-on-write technique. But this can lead to inefficiencies.
Rust solves this problem by keeping track of lifetimes for the objects. This adds a burden to the programmer, and can add unnecessary restrictions to the programs.
Mutable value semantics
Functional programming languages avoid the above issue by forbidding mutation. It’s OK to have multiple references to objects, as nobody can change these objects. This feels unnatural for many programmers, and it’s inefficient for countless algorithms.
Val solves this problem in an entirely different way: it adds restrictions to references, and ensures that nobody can read an object while somebody else is allowed to change it.
Val recognises the importance of whole/part relationships. These can only form a tree, not a cyclic graph. If we want to modify an object of this tree, we immediately know the impact of that change, i.e., all other objects that can potentially affected by this mutation. It allows us to reason what objects are safe to be passed as read and as write into a function.
In the end, following this logic, we can safely add references to represent whole/part relationships.
In the Val model, mutation is not forbidden, but each time we mutate an object, the compiler can compute which objects can be safely read and which objects can be safely written at the same time. Safety can be guaranteed by construction.
Eliminating arbitrary references between objects and focusing on whole/part relationships is what gives Val value semantics. But, because Val also allows mutation of values, we can call this model Mutable Value Semantics. More information about this model can be found in [Racordon22a].
Scientific approach
Reaching this point, it makes sense for me to touch on an aspect that I consider important: Val seems to follow a scientific approach.
The reader can see that in the previous section we (briefly) describe a computation model that ensures safety. It’s not just a claim that the author makes about the language being safe. They have a proof of safety, under the restrictions imposed by the language.
Dimitri Racordon, the main creator of the language, is actually a post-doc researcher. Dave Abrahams also seems to be like-minded. Dave joined Sean Parent to re-form Adobe’s STLabs. The research-oriented influence of Alex Stepanov (creator of STL, and previous member of STLabs) on both Dave and Sean can be seen.
There is no guarantee that Val will be as successful as C++, but one can spot the sound approach of solving some fundamental issues of C++: clearly define the problem and then come up with a general and elegant solution.
Using ad hoc references
Val simply denotes as unsafe the usage of ad hoc references. This makes it unclear how one can implement programs that need references beyond expressing whole/part relationships.
For example, implementing a doubly linked list requires references that cannot be modelled as whole/part relationships. It is not clear how to implement doubly linked lists with mutable value semantics. As another example, consider a shared cache component in an application. By definition, such a component needs to be accessed by multiple parties, and needs to allow mutation. Again, it’s not clear how this can be implemented in Val.
Maybe the simple answer to these examples is that the user must mark some code as unsafe. That may be OK; we, as users of the language, just lack the experience on how these cases would be handled. Val has to provide good guidance for handling such cases.
C++ interoperability
As the time of writing this article, Val has no clear public plan for handling interoperability with C++; it just declared its intention. To become a C++ successor language, Val needs to solve this problem. And, it appears that this problem is not an easy one.
The first thing to notice is that, according to its description, Val is mostly inspired by Swift [Val]. This means that the gap between Val and C++ is not small (larger than the gaps between Carbon and Cpp2 on one side, and C++ on the other side). Closing this gap may require significant effort.
The second obstacle is the restrictions imposed by the mutable value semantics system. C++ inherently contains a lot of ad hoc references. This means, that C++ code would be seen in Val to contain countless unsafe operations. In my mind, it feels that almost all C++ operations ought to be marked unsafe in Val. This seems to increase the interoperability gap.
Please note, I’m not saying that Val can’t properly interoperate with C++; it’s just that implementing this may not be a simple endeavour.
Carbon
Carbon is a language announced as a (possible) C++ successor language at CppNorth 2022 [Carruth22, Carbon]. Carbon is backed by Google (and, according to Chandler, also by Adobe). Furthermore, as an interesting fact, Google was the big name absent at CppCon 2022; maybe this is an indicator that Google is serious about moving away from C++.
In his talk, Chandler, started enumerating the current problems with C++:
- a lot of technical debt (40 years of C++, plus all the technical debt from C)
- C++ prioritises backward compatibility over language evolution; this also prevents fixing technical debt
- the ISO process of language evolution is not optimised for the actual needs of C++ evolution
The solution to these problems, according to Chandler, is to start thinking about a C++ successor language. Similar to how C++ was created to be a successor of C, how Swift was created to be a successor of ObjectiveC and how Kotlin was created as a successor of Java, we need to find a successor language to C++.
To create a C++ successor language, we need builds within the existing ecosystem, provide bidirectional interoperability and ensure we have tools to assist us in migration and learning. And those are actually the goals of the newly announced Carbon language.
Carbon doesn’t seem to have an emblematic feature compared to C++. It just feels like a C++ cleanup project. In the announcement keynote, Chandler showed a cleaner syntax, cleaner pointer semantics, better packaging, better defaults for public/private members, explicit self parameter, inheritance cleanup, API extension points, and C++0x-style generics. All these features are present in other programming languages, in one way or another.
Better defaults
Carbon can be seen as C++ with better defaults. This is a good thing. People will see a familiar language that is just better/simpler. The learning curve for Carbon can be smooth, and the transition from C++ to Carbon made without jumping through too many hoops.
But, on the other hand, how is this different from D? D also attempted to be a C++ successor by learning from C++ mistakes and cleaning its rough edges. What would give the Carbon language its internal coherency and not let it feel like a group of unrelated features?
If we look at this from an evolution perspective, even if all the defaults make a lot of sense today, what guarantees that they would make sense in the following decades? How can we prevent Carbon from accumulating technical debt? A partial answer to this question is, as Chandler mentioned, the use of tools in assisting the migration. But, as we’ve all seen how painful the migration from Python 2 to Python 3 was; probably not everyone is convinced that tools can help up be future-proof.
All these are questions that the Carbon team need to answer. I’m not trying to claim that these are hard questions to answer, but they need to be answered.
Interoperability with C++ is hard
Even if Carbon can be a C++ with better defaults, interoperability with C++ is not necessarily easy. Here are some points brought up by Sean Baxter [ADSP22]:
- there is no function overloading in Carbon
- there is no exception handling in Carbon
- there is no multiple inheritance in Carbon, but people can still use it in C++
- Carbon doesn’t handle raw pointers, unlike C++
- Carbon doesn’t have constructors
Looking at these points, it can be easily seen that interoperability with C++ will be a complex topic. Most probably, even if the interoperability issues can be completely resolved, migrating from C++ to Carbon for large software will not be a simple transition.
The rise and fall of the Culture
Google is a company that strongly believes in culture as a driving force for software development. This was also expressed by Chandler in his keynote with a quote from Peter Drucker:
Culture eats strategy for breakfast, technology for lunch, and products for dinner, and soon thereafter everything else too.
While I do believe that culture in an organisation is essential, just quoting Peter Drucker is not a recipe for success. The main problem is that it’s hard to measure culture and its impact. Chandler lays out a couple of points about culture for Carbon (inclusiveness, community friendly, etc.). While all these points are good points, they are not enough to define culture or to make it work for the Carbon project. For example, Chandler doesn’t mention technical excellence, perseverance, courage to try new things, or how to prioritise different (culture-related) goals.
In one of the previous companies I worked at, we had a mantra that said ‘we never let a project fail’. Does Google and the Carbon project have a similar goal in its culture? People seem to see Google as a company that tries out many products and shuts them down after some time. See, for example, Figure 2 for a tweet from Victor Zverovich [Zverovich22] that capitalises on this perception in a joke about Carbon. This line of thought may not be too far-fetched considering that Chandler also announced that there is a different team in Google that has the same goal, but they start from Rust and move towards C++.
 |
| Figure 2 |
To reiterate: culture is good, and the points that Chandler brought up are good points. But, I’m an engineer: I need verifiable arguments if I’m to be convinced of something.
Governance model
One of the interesting points about the Carbon announcement is the governance model. The Carbon project aims at a governance in which no company dictates the future of the language. Everyone can participate in the evolution of the language by creating pull-requests, but the more important the feature is, the more analysis/argumentation is needed.
For significant features that don’t have consensus, there is a steering committee of three members (Chandler Carruth, Kate Gregory, Richard Smith) that is responsible to reach to a decision. They don’t get the chance to contribute to the design; they just have to weigh the arguments presented to them and make the choice.
It is intriguing to notice that this model tries to emphasise a democratic process, which is somehow similar to the goal that ISO has. It’s just a different division of parties involved, with clearer rules of what to do when an impasse is reached. If the same people that work on C++ standardisation worked on Carbon, it’s not clear if the Carbon process would be significantly better.
While democratic methods are currently the best way to govern, we’ve seen recently a series of major political failures that can be directly correlated to downsides of democracy. And, it’s worth mentioning, in Ancient Greece, democracy was considered a bad way to govern.
Cpp2
CppFront is a project that was announced by Herb Sutter in the closing keynote of CppCon 2022 [Sutter22]. It is a transpiler that converts from a “better C++”, i.e., Cpp2, to old C++. While CppFront / Cpp2 was officially announced this year, Herb has been working on this project for about 7 years; each year, Herb has showcased a small part of Cpp2.
Herb wants to improve C++ significantly (i.e., 10×) rather than performing incremental changes (i.e., 10%). He hopes to bring C++ to that old goal of much simpler and cleaner language that Stroustrup envisioned 30 years ago. And, interestingly enough, takes the same approach that Stroustrup took when he wanted to improve on C: start a new language and translate the code to the previous language. Thus, CppFront is a small transpiler that takes Cpp2 code (Herb’s new language) and outputs regular C++ code.
Herb also sets metrics that we can use to evaluate whether this experiment succeeds: 50 times safer (that is 98% fewer CVEs), and 10 times simpler (90% less total guidance to teach). Defining metrics upfront is a good strategy to be able to evaluate the success of an experiment; I really like this idea.
Backwards compatibility and interoperability
Cpp2 can be simpler than C++ by dropping backwards compatibility. This finally allows the language to remove features that are considered harmful, and to revisit some of the design choices that proved to be suboptimal. By dropping backwards compatibility, Cpp2 can finally address decades of accumulated technical debt in C++.
Truth be told, prioritising backwards compatibility over language evolution in C++ doesn’t have a solid case. Each time we add a major feature to the language (e.g., concepts, coroutines, modules, etc.) we essentially create a new epoch in the language. New code can interact with old code, but old code cannot simply depend on new code written with the new features. Although the C++ standard doesn’t officially talk in terms of language epochs, there is an underlying system of epochs in the language, dictated by the releases of new features.
One can think of Cpp2 as a major new feature to C++. Things are a bit more complicated in terms of interoperability and tooling, but the essence is the same. There are no good technical reasons why old-style C++ cannot coexist with Cpp2 in the same application.
By design, Cpp2 is semantically close to C++; this makes interoperability easier. On the other hand, this can prevent Cpp2 from having entirely different features from C++. For example, it would be hard for Cpp2 to use C++0x-style generics.
Addressing safety
A goal of 50× improved safety sounds impressive. If Cpp2 can deliver this, I believe most users of the language will be happy.
Let’s put this number in perspective, to thoroughly understand the impact. It means that 98% of C++ applications would not crash any more if they were translated to Cpp2 (assuming that crashes are produced only by unsafe applications). Or that 98% of the C++ web applications would not have vulnerabilities (if there are no other non-C++ vulnerabilities). That would be a drastic reduction of crashes and security vulnerabilities.
This seems too good to be true. Actually, if we analyse this in more detail, it appears that these numbers are too high.
First, if we discuss safety, we need to be clear on what safety is. Safety includes:
- type safety
- bounds safety
- lifetime safety
- initialisation safety
- object access safety
- thread safety
- arithmetic safety
The first 4 items on this list are addressed by Herb in his keynote. However, not all the aspects of those safety items were addressed. As a prime example, lifetime safety cannot be guaranteed in the presence of raw pointers; just checking pointers for null is simply not enough. There is also not a single feature announced to detect use-after-delete cases with pointers.
Cpp2, as described in the CppCon keynote, cannot detect the problem with this code:
vec.push_back(vec.front());
Herb defines his safety metric to include the first four safety components; deliberately ignoring the other types of safety seems odd. Especially if the omitted ones are important.
Object access safety refers to safety rules that are influenced by object access patterns. In general, unsafe code in this category can translate into type safety, bounds safety or lifetime safety. The rules for invalidating iterators are great examples for this category.
Thread safety is a big issue in C++ and was not mentioned at all by Herb. In her 2021 C++ Now talk [Kazakova21], Anastasia Kazakova presents data showing that in the C++ community, Concurrency safety accounts for 27% of user frustration. For comparison, bounds safety issues only accounts for 16% and use-after-delete accounts for 15% of user frustration. Concurrency safety is the biggest pain point in terms of safety, and this is not even captured on Herb’s list.
Herb claims on his slide that Cpp2 gets “safety by construction”. That cannot be true. Safety by construction should mean that the language is built in such a way that always lead to safe constructs (unless programmers really ignore the type system and take safety into their own hands) – similar to how Val or Rust is built. But Cpp2 doesn’t do that; it just adds more safety checks for some common sources of unsafe behaviour. This should immediately stand out if the reader has watched the talks given by Dave Abrahams and Dimitri Racordon [Abrahams22a, Abrahams22b, Abrahams22c, Racordon22b], and also Sean Parent’s talk on exceptions [Parent22].
This makes me believe that 50× improvement on safety is not achievable as a goal.
On the measurability of the goals
As I mentioned above, I do love the fact that Herb set up metrics for his experiment. Theoretically, at any point, we can measure the progress against these metrics, and we can assess if the experiment is a success or can lead to success.
Let’s start with the second metric: being 10× simpler, as measured in the guidance we need to teach in C++ books. It’s less likely for people to write books on Cpp2 before this experiment proves to be a success, but we can imagine what the content of such a book would be. We can determine what would be the concepts we need to teach about Cpp2, and we can compare that to the list of things we are currently teaching about C++. Thus, we can measure this metric.
This is not as straightforward as one might think. C++ has a long history; thus we know its pitfalls, and people have documented these in C++ books. But, Cpp2 doesn’t have such a rich history, so there is always the suspicion that we don’t know all its pitfalls. However, Cpp2 being so close to C++, I honestly believe that we can dismiss these concerns and get an accurate measurement on simplicity.
But, I cannot say the same thing about the second metric. How can we measure the percentage of CVEs and safety bugs? We first need to have a sufficiently large corpus of Cpp2 programs, written by a large variety of programmers and companies. However, in order for that to happen, Cpp2 needs to be considered a success – a circular dependency. Thus, the safety metric, as defined in Herb’s talk, is not a good metric to measure the success of the experiment.
Using this metric makes sense to assess the language some time after it has been used in the mainstream, but not to judge the success of the experiment.
To have or not to have monads
At 1h 33 min in the keynote talk (taking the YouTube video as a reference) [Sutter22], Herb Sutter proudly remarks: “I have not said the word monad once”. Then he goes on to explain that Cpp2 is all about language ideas that we are currently using in C++; not weird foreign terms from other languages.
While this remark may appeal to the self-centred part of the C++ community, I believe it hurts the community more than it helps.
First, C++ uses monads all over the place. The new C++23 std::expected feature may be a known example of using monads, but C++ is fundamentally built around monads. We implicitly use monads when we call functions that may throw exceptions – that is, virtually everywhere.
Secondly, it creates a feeling of self-sufficiency within the language users. Instead of opening the community to new ideas, such a statement transmits the message that C++ doesn’t need to learn from other languages. But the huge amount of technical debt the language has, and the appearance of three successor languages, proves otherwise.
Comparison
Table 1 attempts to provide a comparison between the three languages; C++ is also included as a baseline.
|
|||||||||||||||||||||||||||||||||||
| Table 1 |
All three C++ successor languages announced this year are considered to be experiments. We don’t have good indicators whether they will actually succeed in attracting a critical mass of coders/code bases that would use them in production environments.
Looking at the number of stars on GitHub, we see Carbon as the leader of the pack – by a long way, compared to the other two. Carbon has succeeded at creating more hype inside the community; the focus on inclusivity and the governance model might have contributed to this.
The three languages also differentiate themselves in terms of how they resemble C++. As expected, Cpp2 is the closest of the three to C++. Carbon seems further away from C++, but uses the same fundamental building blocks as C++; the user fundamentally thinks in the same terms in Carbon as they used to in C++. Because of Mutable Value Semantics, Val programmers need to have a slightly different mental model when programming, which may present Val as a language further away from C++. On the other hand, if we look at the fast by definition mantra of Val, especially in the context of safe by default and simple, the principles of the language seem to translate well to a C++ audience.
Out of the three new languages, Val is the only one that can back up its promise of safety. The other two try to change some of the defaults for the most unsafe operations; it’s unclear if that makes a large difference yet. If Carbon and Cpp2 don’t feel like languages that you can easily shoot yourself in the foot with, they probably feel like languages that you can easily inflict knife cuts on your legs with.
All three languages seem to improve on C++ in terms of language feature coherence. But changing the defaults doesn’t get you that far in terms of language coherency. Here, Val’s approach seems slightly more cohesive compared to Carbon and Cpp2.
Finally, the point which I believe is important in an engineering discipline like ours: how many of the language design decisions are backup by some sort of science? In this respect, Val seems to be the only one that has some theoretical foundation. This can provide real guarantees to its users.
Personal take
Herb started his keynote with a plea not to abandon C++. It’s a testament, from C++ leadership, that people are considering abandoning C++. The appearance of three C++ successor languages in a single year just confirms the same idea. Whether C++ is starting to lose popularity or not is not yet known, but we can probably assume that this year is an inflection point for the future of C++.
Currently, it’s too early to tell whether any of these experiments will succeed or not. All languages have strengths, and all of them have weak points. If at least one of them succeeds, I believe we advance the practice in programming languages; that probably means a positive impact in the software industry overall.
As much as possible, I have tried to be objective in this comparison, but I do have my biases. I hope that they didn’t prevent me doing a decent job of comparing these languages.
Speaking of biases, I do need to confess: in my spare time, I have started working with the Val team to push the core ideas of the language forward. To me, the ideas, if they can be perfected and adopted successfully in practice, are more important than particular languages. If Val dies as a programming language but all its ideas are incorporated in C++, then I will be delighted.
I have been captivated by the ideas of mutable value semantics since I saw the recordings of Dave and Dimitri’s talks from C++ Now [Abrahams22a, Abrahams22b]. I distinctly remember at that point that I contemplated writing an Overload article on the subject; well, here we are. Meeting Dave and Dimitri at CppCon 2022 and spending time with them walking through the details, convinced me that the ideas behind Val are profound, well thought through, and that they deserve close attention.
Looking at the popularity numbers, Val doesn’t do that well. Probably one of the reasons for this is the fact that good ideas take time to settle in. To paraphrase a famous speech, I chose to work on Val, not because it’s easy, but because it’s hard; because Val’s goals are worthwhile.
References
[ADSP22] Connor Hoekstra, Bryce Adelstein Lelbach, Connor, Sean Baxter, ADSP: The Podcast, Episode 97: ‘C++ vs Carbon vs Circle vs CppFront with Sean Baxter’, 2022, https://adspthepodcast.com/2022/09/30/Episode-97.html
[Abrahams22a] Dave Abrahams, A Future of Value Semantics and Generic Programming (part 1), C++ Now 2022,
https://www.youtube.com/watch?v=4Ri8bly-dJs
[Abrahams22b] Dave Abrahams, Dimitri Racordon, A Future of Value Semantics and Generic Programming (part 2), C++ Now 2022, https://www.youtube.com/watch?v=GsxYnEAZoNI&list=WL
[Abrahams22c] Dave Abrahams, ‘Values: Safety, Regularity, Independence, and the Future of Programming’, CppCon 2022
[Carbon] GitHub, Carbon Language: An experimental successor to C++, https://github.com/carbon-language/carbon-lang
[Carruth22] Chandler Carruth, ‘Carbon Language: An experimental successor to C++’, CppNorth 2022, https://www.youtube.com/watch?v=omrY53kbVoA
[Kazakova21] Anastasia Kazakova, ‘Code Analysis++’, CppNow, 2021, https://www.youtube.com/watch?v=qUmG61aQyQE
[Parent22] Sean Parent, ‘Exceptions the Other Way Around’, https://www.youtube.com/watch?v=mkkaAWNE-Ig
[Racordon22a] Dimitri Racordon, Denys Shabalin, Daniel Zheng, Dave Abrahams, Brennan Saeta, ‘Implementation Strategies for Mutable Value Semantics’
https://www.jot.fm/issues/issue_2022_02/article2.pdf
[Racordon22b] Dimitri Racordon, ‘Val Wants To Be Your Friend: The design of a safe, fast, and simple programming language’, CppCon 2022, https://www.youtube.com/watch?v=ELeZAKCN4tY&list=WL
[Stroustrup94] Bjarne Stroustrup, The Design and Evolution of C++, Addison-Wesley Professional, 1994
[Sutter22] Herb Sutter, ‘Can C++ be 10× simpler & safer … ?’, CppCon 2022, https://www.youtube.com/watch?v=ELeZAKCN4tY&list=WL
[TIOBE22] TIOBE, TIOBE Index for October 2022, October 2022, https://www.tiobe.com/tiobe-index/ (last accessed October 2022)
[Wikipedia] Wikipedia, C++, https://en.wikipedia.org/wiki/C%2B%2B#Criticism
[Val] The Val Programming Language, https://www.val-lang.dev/
[Zverovich22] Victor Zverovich, ‘Google will soon have…’, Twitter, 2022, https://twitter.com/vzverovich/
has a PhD in programming languages and is a Staff Engineer at Garmin. He likes challenges; and understanding the essence of things (if there is one) constitutes the biggest challenge of all.

