








I've always found that you don't learn anything until you try to actually do it. In this article I provide a practical chance to learn some new C++ knowledge. If you fancy getting your hands dirty here then you might pick up some valuable new techniques. This is a gentle introduction to writing robust STL-like generic containers.
Recently I needed a circular buffer to implement some low level logic. These data structures aren't exactly complicated to write, but it got me thinking. That's a dangerous thing at the best of times. I've never written an STL-style container before, and I'd never come across an STL-like circular buffer [ 1 ] .
With a somewhat gung-ho attitude I began to implement an STLcompatible circular buffer class. I'm not going to say I've got it perfect but I present here my journey of discovery in the hope that it will be useful. You have the chance to cover a lot of the same ground I did since I'll take us on this journey via a few "exercises" - just a little something to get you thinking.
Put as much effort into the exercises as you like. As with so many things, the more effort you put into it, the more you'll get out at the end.
What is a circular buffer?
Before we delve into the murky depths of the STL let's take a quick refresher course in circular buffers.
There are a number of fundamental data structures in computer science. The array is about as basic as it comes, its implementation essentially requires a base pointer to some allocated memory, and an index into it. You could perhaps argue a stack is even more basic: if you don't want to check for the location of top of the stack you only need a single "current location" pointer. Textbook examples of stack code are generally implemented in terms of an array, though.
Coming hot on the heels of these two faithful friends is the good old circular buffer. It looks like an array but has FIFO consumption semantics [ 2 ] , can smell really quite like an array, but gives the pretence of being infinite in size. How does it do this? This is where the circular bit comes into play. The logical buffer is considered to 'wrap around' the physical array it is implemented inside. The 'head' and 'tail' of the buffer chase each other around the implementation array.
The following diagram may help envision this.
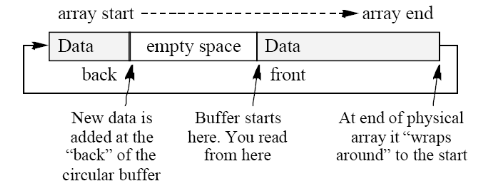
Circular buffers have a number of uses. For example, device drivers that constantly receive data (like a serial port), and need to buffer it often use circular buffers - acting as a data 'producer' for the client code. It is the client's responsibility to consume the data about as fast as it is produced to ensure that no data is lost. This makes reasoning about the data exchange easier. The circular buffer helps here since the producer (driver) only needs to worry about adding data to the end of the circular buffer, whilst the consumer only needs to worry about reading from the front.
A simple C++ circular buffer class interface would look like this. For the moment, let's presume that the buffer just stores int s:
class simple_cbuf {
public:
enum { default_size = 100; };
explicit simple_cbuf(size_t size =
default_size);
~simple_cbuf();
size_t size() const;
bool empty() const;
int top() const; /* see below */
void pop();
void push(int new_value);
private:
/* whatever you want */
};
Note that here we separate top and pop . Some implementers might like a single atomic top-and-pop function. However, this approach keeps consistency with the STL vector -like interface which will help later on. There is also a practical reason to split the two functions - it makes exception safety issues easier to reason about. More on this later.
Exercise #1
Implement this simple class API. At this stage it's OK to store
the data in a dynamically created array
[
3
]
.
Hopefully that exercise made you wonder what to do in push when the buffer is full. If we want to "pretend" to be of infinite size then somewhere along the way some data will have to be thrown away. There are two choices:
-
throw away the new data, and leave the simple_cbuf state unchanged, or
-
throw away the data at the 'front' of the circular buffer and replace it with the new 'end' data.
In practice the latter case is often required - this is the whole point of the circular buffer (the first method is really rather like a fixed size array, after all). It might be nice to provide a policy option to select what behaviour you want. Our final solution will allow us to make this choice with no extra cost.
Did you think about copy construction and copy assignment? Basing our implementation on a dynamically created array will mean that we'll need to provide correct behaviour for these two members. They must be either declared as private and unimplemented, or added to the class' public API.
Random access?
Now here's an interesting usage question, the above minimal interface doesn't allow us to randomly access the buffer. In this respect it just looks like a stack. This isn't too hard to do, though - try exercise two.
Exercise #2
Implement an
operator[]
for the
simple_cbuf
.
This should be fairly simple to do, there's just one thing to watch out for. For maximum usefulness we need to provide two versions of operator[]; one 'normal' version for non-const objects, and one for const objects. This allows us to provide assignment into the simple_cbuf . You should end up with two functions whose signatures are thus:
int &operator[](size_t); const int &operator[](size_t) const;
This is the canonical form of these functions, although for an int-holding container we perhaps don't need to pass a const int& from the const operator[] , we could get away with just an int return type. We'll stick with this because it's good practice.
Now we have something that looks a quite like an array, but with more usual circular buffer FIFO characteristics.
With this kind of behaviour is this data structure genuinely useful? Does it have any benefits over a plain array? Actually it can be very useful, but it would be limited to a smaller set of problems than something like, say, an STL vector .
Make it generic
So we now have a pretty complete simple_cbuf class, but it only works for int s. The final introductory step is to make it generic.
Exercise #3
Add a line
template<typename T>
to
the beginning of
the class definition and modify the code accordingly.
How much of the public API do you need to modify?
This really isn't too onerous. Obviously if you were thinking about separate cbuf.h and cbuf.cpp files you now want to munge the function definitions into the header file, but it's largely a case of selectively replacing of int s with T s.
The second question: "How much of the public API do you need to modify?" is worth considering. For a simple integer circular buffer you can pass parameters to push by value. However since T could now be any class type you really want to pass by const& . Also should top return a T by value, or by const& ? The latter makes more sense, since it prevents clients from being stupid with a temporary object by writing something like:
cbuf.top() = T(); // meaningless; no part
// of cbuf would be modified by this,
// despite what it looks like
Our choice of return type for operator[]() const is now also vindicated.
So now we have seen what a circular buffer is, how to use it and how to implement a fairly basic example case. The rest can't be that hard, can it?
Moving towards the STL style
Now we'll start to write an STL style container that's based on the class we've developed above. I'm going to presume at this point that you're familiar with using the STL and its definitions of container class interfaces [ 4 ] . What do we need to provide to make this circular buffer class more STL-like?
-
standardised typedef s like value_type etc,
-
standardised API names,
-
iterators (forward, reverse, random access),
-
use allocators for memory operations, and
-
to be maximally useful, exception safe (and also exception neutral)
We'll start adding this functionality in stages and consider what we're doing at each point.
Our implementation will start off template based, using a dynamically created array as the internal data storage implementation. So here's the initial framework of our class, not yet worrying about any of the above list of items to include. We'll flesh it out as we go along:
template <class T>
class circular_buffer {
public:
explicit circular_buffer(
size_t capacity = 100)
: array_(new T[capacity]),
array_size_(capacity),
head_(0), tail_(0),
contents_size_(0) {}
~circular_buffer()
{ delete [] array_; }
/* ... */
private:
T *array_;
size_t array_size_;
size_t head_;
size_t tail_;
size_t contents_size_;
};
Step 1: Some standard type definitions
To work with STL components we need to provide these definitions in the public API of our class [ 5 ] :
value_type // The type of the
// container's elements.
Pointer // A pointer to the
// element type.
const_pointer // As above, but const.
Reference // A reference to the
// element type.
const_reference // As above, but const.
size_type // The type used to index
// into the container.
difference_type // The type of the result
// of subtracting two
// container iterators.
Exercise #4
What should they be?
No rocket science yet. At this stage, my choice was:
typedef T value_type;
/* T is template param */
typedef T *pointer;
typedef const T *const_pointer;
typedef T &reference;
typedef const T &const_reference;
typedef size_t size_type;
typedef ptrdiff_t difference_type;
Now the original framework code can be slightly modified - I'll change the variable and parameter types from size_t to size_type and for array_ from T* to a value_type* . Is this too picky? No, it will aid future maintainability. If one of these definitions needs changing later (hint - it will) then the change can be made in one place and apply to all the code we've written.
Step 2: Appropriate function names and implementations
Now, in the vector API we have front , back , push_back , pop_back and clear . We'd like those (or something akin to them). We'll clearly not provide pop_back , instead there will be pop_front for good circular buffer measure.
Exercise #5
How would you implement these?
Take care over function signatures to ensure maximal
efficiency in the light of template types.
front and back are pretty simple. There's just one thing to watch out for here, appropriate const and non- const versions:
reference front()
{ return array_[head_]; }
reference back()
{ return array_[tail_]; }
const_reference front() const
{ return array_[head_]; }
const_reference back() const
{ return array_[tail_]; }
What happens if you call these when the circular buffer is empty? It's an invalid call and we define this to result in unspecified behaviour . We could provide a 'safe' version of the circular_buffer class later on that does checking, but we don't want to be burdened by it unnecessarily. It is up to the user to call us in a consistent and valid manner.
The clear member function is also reasonably simple:
void clear()
{ head_ = tail_ = contents_size_ = 0; }
In order to implement the final two functions, I'd define these private helper functions:
void increment_tail() {
++tail_;
++contents_size_;
if (tail_ == array_size_) tail_ = 0;
}
void increment_head(){
// precondition: !empty()
++head_;
-contents_size_;
if (head_ == array_size_) head_ = 0;
}
Now push_back and pop_front can be implemented along the following lines. It's actually a reasonably verbose push_back implementation, but will show exactly how we reason about the contents of the circular buffer, and where head_ , tail_ , and contents_size_ fit into the equation:
void push_back(const value_type &item) {
if (!contents_size_) {
array_[head_] = item;
tail_ = head_;
++contents_size_;
}
else if (contents_size_ != array_size_)
{
increment_tail();
array_[tail_] = item;
}
else {
// We always accept data when full
// and lose the front()
increment_head();
increment_tail();
array_[tail_] = item;
}
}
void pop_front() { increment_head(); }
Again with pop_front we'll insist the user only calls the function when it is semantically valid, making our life a lot easier. Don't think we're being unnecessarily lazy here; this is exactly what the standard vector does!
For the record, can we coalesce some of that sloppy push_back logic above? Indeed we can, if we apply a few other minor modifications to the class:
void push_back(const value_type &item) {
increment_tail();
if (contents_size_ == array_size_)
increment_head();
array_[tail_] = item;
}
That looks nicer. To get here we have removed the special case of an empty buffer. To cope with this we need to set the member variables to a different pre-ordained state. The constructor and clear should initialise tail_ and contents_size_ to zero as before. head_ should now though be set to 1 .
Step 3: More simple functions
You won't get many points for these simple functions, but they make for a consistent container API.
Exercise #6
Implement the following simple functions:
size_type size() const; size_type capacity() const; bool empty() const; size_type max_size() const;
They're all self explanatory except for max_size . This function returns the largest possible size of the container. A reasonable example implementation is:
size_type max_size() const {
return size_type(-1) /
sizeof(value_type);
}
An alternative is to use std::numeric_limits<size_type>::max() . However, this requires that we include the <limits> header file and we'll avoid that for the moment.
Step 4: Random access
We want to implement iterators, and this requires that we provide general access to our circular buffer via operator[] . We implemented this in exercise #2, so we need to move this over to our new class. However, to be more thorough and more vector -like we can observe that vector also provides the at function, that provides a checked access, whilst the operator[] only provides unchecked access.
Exercise #7
Implement both
const
and non-
const
forms of
operator[]
and at for
circular_buffer
.
Now our circular buffer is randomly accessible we can move onwards and upwards...
Step 5: Implement an iterator
In exercise #2 we said that it was debatable whether the operator[] functions should have been added to the circular buffer class. Certainly in a traditional circular buffer design you wouldn't have them. However, part of the point of this whole exercise is to learn how to write a generic container that can be iterated over, which will make it compatible with standard library algorithms. Because of this we should be able to randomly access data in the circular buffer.
If you hold to the view that buffer data may be read, but may not be written by random access, then you will only implement the const version of operator[] and only provide a const_iterator . However, for the full STL "experience" we'll allow the non- const operator[] and provide both mutable types of iterators.
We'll start off by considering how to write a non- const forward iterator, and work up from there.
The simplest example of an iterator would be for an array - the iterator type would be a simple pointer. The "end" iterator would be a pointer to one-past-the-end of the array. We can't simply use a pointer to iterate over our circular buffer, so we'll have to define our own class type. For obvious reasons we'll call it circular_buffer_iterator .
Exercise #8
What data members does
circular_buffer_iterator
require?
To iterate over a circular_buffer effectively we only need to know which the circular_buffer is and at what index we currently stand. However, circular_buffer is a template type so how can we refer to it? We'll make the iterator a template class too, dependant on the type of the circular buffer. We could make it dependant on the value_type of the circular_buffer, but we choose not to. Why? Because later on we'll add more template parameters to the container class and that would make the alternative iterator implementation prohibitively complex.
Should we store a pointer or reference to the circular_buffer ? They are equivalent for these purposes - if a reference became stale the iterator could be considered to have become invalid anyway, using the iterator would then be invalid. However, since we need to implement operator== for the iterator class, it's easier to compare pointers, so that's what we'll choose.
This means we start off with a class like this:
template<typename T>
// T is circular_buffer type
class circular_buffer_iterator {
public:
typedef T cbuf_type;
circular_buffer_iterator(
cbuf_type *b, size_t start_pos)
: buf_(b), pos_(p) {}
/* ... */
private:
cbuf_type *buf_;
size_t pos_;
};
There's a lot of operations we need to define for this class. But first, we need to add the appropriate typedef and functions into circular_buffer class to meet STL requirements [ 6 ] :
typedef
circular_buffer_iterator<self_type>
iterator;
iterator begin()
{ return iterator(this, 0); }
iterator end()
{ return iterator(this, size()); }
We'll have appropriately defined self_type , naturally.
STL iterators are required to define a number of typedef s. These are:
iterator_category // See below.
value_type // Type of element
// iterator 'points
// to'.
size_type // Container index
// type.
difference_type // Container difference
// type.
Pointer // Type of a pointer to
// element.
const_pointer // As above, but const.
Reference // Type of a reference
// to element.
const_reference // As above, but const.
Don't they look suspiciously like the typedef s in the container class? Does that give you a clue how to implement them? [ 7 ] But what's that iterator_category definition for? This is a type as defined by the C++ standard that defines what operations are valid on the iterator. We can choose what kind of iterator to provide, and define it here. The simplest is a forward iterator , the most comprehensive a random access iterator . For the moment we'll compromise: our iterator will be a bidirectictional iterator , so we'll set this to bidirectional_iterator_tag [ 8 ] .
Exercise #9
What operations should an iterator support? How do you
implement them?
Obviously, we need to dereference an iterator. That means we need to provide an implementation of operator* and operator-> . They're not hard. The following code does the trick:
T &operator*()
{ return (*buf_)[pos_]; }
T *operator->()
{ return &(operator*()); }
The other operations on an iterator type are reasonably simple. We don't have to do too much error checking; remember that incrementing an iterator past end() is invalid and results in undefined behaviour.
Exercise #10
For a bidirectional iterator we need to implement the follow
functions. How would you do this?
self_type &operator++() self_type operator++(int) self_type &operator-() self_type operator-(int)
These are some simple random access iterator operations that
we can also implement here. How will you provide these?
self_type operator+(difference_type n) self_type &operator+=(difference_type n) self_type operator-(difference_type n) self_type &operator-=(difference_type n) bool operator==(const self_type &other) const bool operator!=(const self_type &other) const
What are the differences between the two forms of
operator++
and
operator-
?
Answering the last question first, remember that these two forms are pre- and post-increment/decrement (respectively). Take care over the canonical forms of all of the above functions. As a guide, here are the implementations of operator++ , operator+ and operator+= (for a suitable definition of self_type):
self_type &operator++() {
++pos;
return *this;
}
self_type operator++(int) {
self_type tmp(*this);
++(*this);
return tmp;
}
self_type operator+(difference_type n)
{
self_type tmp(*this);
tmp.pos_ += n;
return tmp;
}
self_type &operator+=(difference_type n) {
pos_ += n;
return *this;
}
operator== and operator!= are made easier since we decided to store pointers to the circular_buffer and not references.
Step 6: A const iterator
Exercise #11
How different from the above iterator interface is a
const
iterator interface?
The answer is, not much. We'll need to point to a const circular_buffer , return const references to the buffer data when deferenced, and that's about it. It seems a little bit of a shame to rewrite another class that is almost identical to the one we already have. To prevent too much duplicated code we can factor out the commonality. How best do we do this? Write one class and move out the policy decisions to template arguments.
Unfortunately it's not quite as simple as defining the existing template parameter T (circular buffer type) to be a const circular_buffer . We need to determine the type of reference to return (i.e. choose between circular_buffer 's reference or its const_reference types). We can make this another parameter, and we're almost there. What we've got now is:
template<typename T,
typename elem_type =
typename T::value_type>
class circular_buffer_iterator {
public:
/* ... */
elem_type &operator*();
elem_type *operator->();
};
Providing a default type for this means that our original circular_buffer::iterator typedef is still correct. The rest is the same, even the definitions of these operators. To create a const iterator we just need to instantiate the iterator class with
<const circular_buffer, const circular_buffer::value_type>
There is only one problem left with our reverse iterator implementation. You need to be able to convert from a non-const iterator to a const one so we can write code like:
circular_buffer::const iterator i =
cbuf.begin();
where cbuf is a non- const circular buffer. The path of least resistance for implementing this is to add another template parameter T_nonconst (putting it after T ), which is the same as template parameter T , but without any const qualification. We can then write the following few lines and get the desired conversion:
circular_buffer_iterator (
const circular_buffer_iterator<
T_nonconst, T_nonconst,
dir, typename
T_nonconst::value_type>
&other )
: buf_(other.buf_), pos_(other.pos_) {}
friend class
circular_buffer_iterator<
const T, T,
dir, const elem_type>;
Naturally, we now add a typedef definition for reverse_iterator to the circular_buffer class. We can now do most normal iterator operations. One more thing to consider for now...
Step 7: A reverse iterator
If we can iterate forwards then we can also iterate backwards. Conventional STL containers provide this functionality, returning reverse iterators from their rbegin and rend member functions. A reverse iterator starts (logically enough) at the last element in the container. Every time you increment it, it will actually step back one element. rend points to the 'one-past-the-front' element of the container. Providing reverse iterators means we can apply all the standard algorithms backwards as well as forwards without writing any new algorithm code.
Exercise #12
How would you modify the iterator class we've already made
to create a reverse iterator?
There's two ways to do this. The easy way, or the hard way. Choose! I took the high road, but we don't have to when the low road is perfectly acceptable. At first I created my own reverse iterator class in a similar manner to the const iterator; cunning additional template parameters.
However, to make our life that little bit easier the STL provides an iterator adaptor that automatically creates a reverse iterator for you, based on your forward iterator implementation. I noticed that just a little bit too late, although I was pretty happy that my reverse iterator looked so much like the standard library one! Using this STL facility is by far the better option. It is likely to contain fewer bugs (hopefully none), and will more likely behave in a manner our users expect.
So how do we use this STL magic? Just add the following lines to the circular_buffer typedef s:
typedef
std::reverse_iterator<iterator>
reverse_iterator;
typedef
std::reverse_iterator<const_iterator>
const_reverse_iterator;
That's it. If you really want to understand what's going on in the reverse_iterator template class, think how you would implement your own version. Consider how you would represent rend() bearing in mind that our index type ( size_type ) is unsigned and the one-past-the-beginning index would be -1. Solve that conundrum and you've done the hard work of a reverse iterator implementation.
What have we achieved?
So far we have created a circular buffer class that looks pretty similar in API and usage conventions to the other STL containers. This means that any C++ programmer can pick the class up and use it pretty much immediately with no steep learning curve. It also means that, thanks to the iterators we have provided, the class can immediately be used with all the standard library algorithms currently available.
Of course, there's still more work we need to do…
Next time
We'll look into working with standard library allocators and knitting up exception safety issues. There are one or two more functions to provide which we'll look at too - look over what we've done and see if you can work out what's left.
[ 1 ] There may be a good reason; it's a moot point whether such a data structure is a genuinely useful thing. Still, why let that stop us?
[ 2 ] FIFO: First In First Out. You can only add data to the end of the "array" and consume from the "front". Imagine sending ping pong balls down a thin vertical tube, the order you get them out at the bottom is the order you put them in at the top.
[ 3 ] If you don't know why this might be a problem later on don't worry - you'll find out soon enough. (Well, in the second part of this series.)
[ 4 ] If you want to view an online reference of the STL interfaces, there is one publicly available from http://www.sgi.com/tech/stl/ .
[ 5 ] Actually, there's more (including iterator definitions) but we'll start here.
[ 6 ] We'll also have to add a const_iterator definition, but we'll come to that in the next section.
[ 7 ] Whilst I typedef these here based on the container typedef s, you can alternatively make your life easier by using the std::iterator template class definition.
[ 8 ] Don't worry, we'll make this a full random access iterator in the next article.

