








A mutex is a general purpose tool - there may be better solutions in specific circumstances. George Shagov presents one such alternative.
Introduction
The article might be of interest for server developers in a multi-user multi-threaded multi-processor environment with high data flow capacity, where performance stands on the very edge of the business. (Note that the approach presented here is restricted to systems where the application runs on a single core, and that extreme care should be taken applying it to further processor architectures. - Ed) The basic objective is to represent another approach to the locking mechanism, well-known as mutex objects. Sometimes synchronization objects are the very edge of performance, in some systems locking might take up to 30 percent of total performance, which is quite annoying, since in order to improve the performance it is required to change the architecture of the system, if it is possible of cause, sometimes for certain reasons it is not.
Classical mutex
I do not want to spend your time explaining how mutexes work, yet I think it is important to refresh this knowledge in order to understand the basic idea of the article, and all the consequences which follow. The realization of the synchronization object basically depends on the CPU architecture, let us consider an Intel x86 based one. Basically the mutex object itself is but an integer value (if we are talking about non re-entreat objects). The mechanism of obtaining the lock is usually (this is a very general assumption) performed by means of the assembler XCHG instruction, which exchanges two values. So if we set EAX register to 0 and will perform XCHG EAX , DWORD PTR [EBP] , where EBP points out to the mutex (which is integer), all we need to do after is to check the EAX value, ( 0 represents a lock with 1 being a fail). The crucial thing I did not mention is the LOCK prefix that must be used before XCHG instruction, which locks the BUS during XCHG . Actually that's it. It works perfectly fine, the basic problem is this prefix LOCK , since locking the BUS is quite a costly operation from the perspective of view of performance.
Surprise
What we can do in order to make this operation lighter is to merely remove the LOCK prefix before the XCHG instruction. And that will work, since XCHG is an atomic operation and we assume we are talking about a single CPU system; in a multiple CPU environment, it will definitely fail.. This limitation does look strong, and so it is, but in some cases it might help, in particular where I am describing 'Limitation and usage' in the section below.
It may seem that we could remove the LOCK prefix, but on closer examination this would gain nothing:
The XCHG (exchange) instruction swaps the contents of two operands. This instruction takes the place of three MOV instructions and does not require a temporary location to save the contents of one operand location while the other is being loaded. When a memory operand is used with the XCHG instruction, the processor's LOCK signal is automatically asserted. This instruction is thus useful for implementing semaphores or similar data structures for process synchronization. See "Bus Locking" in Chapter 7, "Multiple-Processor Management" of the IA-32 Intel® Architecture Software Developer's Manual, Volume 3A, for more information on bus locking.[ Intel06 ]
The AMD has the same.
I do not know for what reason they have done that, but that is the fact, probably it means some kind of a protection from a fool, I honestly do not know. So, it might seem like this is a dead end. Actually, it is not.
Logical lock
Let us say we do limit the amount of the users by means of some prior known value, for instance 32. Let us say that our synchronization object will be 32-bit value, an integer, a bit mask, let us say that each particular bit of this mask corresponds to one particular customer (a thread), let us say each thread has and knows its id, let us say each thread is allowed to change only the corresponded bit in the bit-mask, and not allowed to modify any other bit, yet is allowed to check any bit in the bit-mask. Have you got the point? As simple as that, the algorithm of getting lock for thread with number K in case of non re-enter able synchronization object might look like figure 1. The steps are described on the next page.
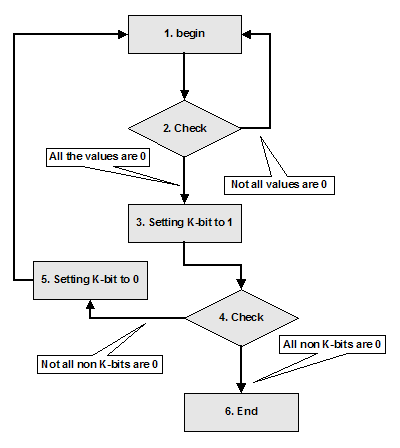
|
| Figure 1 |
- The beginning of the algorithm.
-
Checking that all the values of the bit mask are 0. (This step might have been omitted). And here we have two options:
- All the values are 0. It means the mutex is in non-signalled state and we are allowed to get a lock
- Not all the values are 0. The mutex is in signalled state, some thread has got the lock already. This is the very time to perform spinning and then to go to the beginning of the algorithm.
- Customer with number K is allowed to modify only K-th bit in the bit mask. On this step the modification is performed.
-
It might have happen some other customer has got the lock during this time (from step 2 to 4) therefore we need an additional check here. We need to check that all non-K bits in the bit mask are 0, there are two options also:
- All non-K bits in the bit mask are 0, it means we have got the lock.
- Not all non-K bits in the bit mask are 0, it means we must reset K-th bit in the bit mask to 0 (step 5) and go to the beginning of the algorithm.
The code is absolutely simple and to post it here would be the waste of the space, the only think to consider is the third and fifth step, which are to be done in assembler, my version is in Listing 1.
/*
* set (step 3)
*/
.globl nl_nr32_set
.type nl_nr32_set, @function
nl_nr32_set:
pushl %ebp
movl %esp, %ebp
movl 8(%ebp), %edx
movl 12(%ebp), %eax
orl %eax, (%edx)
popl %ebp
ret
.size nl_nr32_set, .-nl_nr32_set
/*
* reset (step 5)
*/
.globl nl_nr32_reset
.type nl_nr32_reset, @function
nl_nr32_reset:
pushl %ebp
movl %esp, %ebp
movl 8(%ebp), %edx
movl 12(%ebp), %eax
and %eax, (%edx)
popl %ebp
ret
.size nl_nr32_reset, .-nl_nr32_reset
|
| Listing 1 |
C interface for these functions:
extern void nl_nr32_set(
volatile word32* synchronisation_mask,
word32 thread_bit);
extern void nl_nr32_reset(
volatile word32* synchronisation_mask,
word32 thread_bit);
Does it work? Approximately four times faster than classical mutex. Which is quite obvious since the value of the mutex gets cached. Therefore we must say:
Once again
Generally it does not work, since in general case we have a multiple CPUs and each particular CPU has its own cache, therefore in multi-processor environment the algorithm will definitely fail.
It means in order to have got this working we must place all the threads in one CPU, which looks quite strong limitation.
Some data
The first test (see Table 1) creates a thread which locks the mutex and unlocks the mutex, and thus it does for one minute, the amount of locks/unlock is outputted.
|
||||||
| Table 1 |
The second test (see Table 2) creates 8 threads and each one locks the mutex and unlock it, for one minute, the amount of locks/unlock is outputted.
|
||||
| Table 2 |
Such poor number of locking count under Windows I can not explain, this is a question rather to be asked to Microsoft.
There are something to consider here, videlicet a spin-time. On some systems (let me say thus) it significantly changes the result. I am not going to analyse the matter; the only one thing I intend to say is that applying such a lock needs to be diligently considered and measured in each particular case and all the benefits and disadvantages must be taken in account. Such a lock is a very tricky way to get the performance and applying such a one without understanding might lead to unpredictable results.
Limitation and usage
The limited amount of threads and requirement to have all these threads executed on one CPU are to be considered as strong limitations. Notwithstanding there are some certain areas where this invention might have been successfully used, for instance:
- Let us consider some multi-threaded business server, which has some kind of the data collection which is intensively used by means of one or two threads, one thread for instance provides the pretty high flow of the incoming data which are supposed to be added at the collection, the second performs some kind of a calculation, and probably removal of the data from the collection and also there are some amount of threads which lazily query the collection. I would presume the task is quite common. In this case these two threads, which have a high flow of the data might use the locking mechanism, described above. It is important to remember these two threads are to be started on one CPU, moreover we need an additional stuff of threads which are to be started on the same CPU which will perform query operation. This approach will cause some performance degradation for querying threads, yet it will boost up the performance of the first two threads. Thus it becomes possible to get the benefit.
- Let us consider a game server, which offers a skirmish service. It is quite clear what must be done here. All the members (their threads) of one game must be placed on one CPU (though we do limit their amount), and thus we swerve from common locking mechanism. Unfortunately I can not tell you how much percentage of the performance might be taken here, I tried to contact the companies who offer such services but have not had an answer.
- Here I must mention different chat and conference virtual rooms, the only problem is the limited amount of the users.
- I can not avoid the mention of PC boxes, most of them have only one CPU, therefore in some cases classical locks might be considered as redundant.
- One more interesting thing to consider. The algorithm must perfectly on in case multi-core processors, if they use one cache.
In conclusion
I must say the know-how must be diligently considered before use and additional investigation must be done on each particular case, which seems to be quite heavy to apply. Notwithstanding, this is a way to go for those developers who deal with the application where performance is a key issue, such as real-time systems.
References
[ Intel06] IA-32 Intel® Architecture Software Developer's Manual. Volume 1: Basic Architecture. Order Number: 253665-018. January 2006

