








Debugging any program can be difficult. Sergey Ignatchenko and Dmytro Ivanchykhin develop a mathematical model for its complexity.
Disclaimer: as usual, the opinions within this article are those of ‘No Bugs’ Bunny, and do not necessarily coincide with the opinions of the translator or the Overload editor. Please also keep in mind that translation difficulties from Lapine (like those described in [ Loganberry04] ) might have prevented providing an exact translation. In addition, both the translators and Overload expressly disclaim all responsibility from any action or inaction resulting from reading this article.
Debugging programs is well-known to be a complicated task, which takes lots of time. Unfortunately, there is surprisingly little research on debugging complexity. One interesting field of research is related to constraint programming ([ CP07 ][ CAEPIA09 ]), but currently these methods are related to constraint-based debugging, and seem to be of limited use for analysis of debugging complexity of commonly used program representations. This article is a humble attempt to propose at least some mathematical models for the complexity of debugging. It is not the only possible or the best possible model; on the contrary, we are aware of the very approximate nature of the proposed model (and of all the assumptions which we’ve made to build it), and hope that its introduction (and following inevitable criticism) will become a catalyst for developing much more precise models in the field of debugging complexity (where, we feel, such models are sorely needed).
Basic model for naïve debugging
Let’s consider a simple linear program which is N lines of code in size. Let’s see what happens if it doesn’t produce the desired result. What will happen in the very simplistic case is that the developer will go through the code in a debugger, from the very beginning, line by line, and will see what is happening in the code. So, in this very simple case, and under all the assumptions we’ve made, we have that
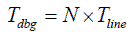
where T line is the time necessary to check that after going through one line, everything is still fine.
So far so obvious (we’ll analyze the possibility for using bisection a bit later).
Now, let’s try to analyze what T line is about. Let’s assume that our program has M variables. Then, after each line, to analyze if anything has gone wrong, we need to see if any of M variables has gone wrong. Now, let’s assume that all our M variables are tightly coupled; moreover, let’s assume that coupling is ‘absolutely tight’, i.e. that any variable affects the meaning of all other variables in a very strong way (so whenever a variable changes, the meaning of all other variables may be affected). It means that, strictly speaking, to fully check if everything is fine with the program, one would need to check not only that all M variables are correct, but also (because of ‘absolutely tight’ coupling) that all combinations of 2 variables (and there are C ( M ,2) such combinations) are correct, that all combinations of 3 variables (and there are C ( M ,3) such combinations) are correct, and so on. Therefore, we have that
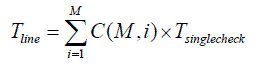
where
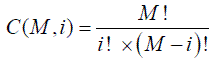
and T singlecheck is the time necessary to perform a single validity check.
Therefore, if we have a very naïve developer who checks that everything is correct after each line of code, we’ll have
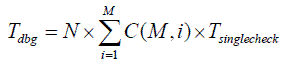
which is obviously (see picture) equivalent to

Optimizations
Now consider what can be done (and what in the real-world is really done, compared to our hypothetical naïve developer) to reduce debugging time. Two things come to mind almost immediately. The first one is that if a certain line of code changes only one variable X (which is a very common case), then the developer doesn’t need to check all 2 M combinations of variables, but needs to check only variable X , plus all 2-variable combinations which include X (there are M -1 of them), plus all 3-variable combinations which include X (there are C ( M -1,2) of them), and so on. Therefore, assuming that every line of code changes only one variable (including potential aliasing), we’ll have
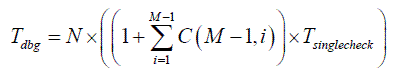
or
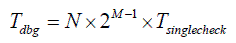
Therefore, while this first optimization does provide significant benefits, the dependency on M is still exponential.
The second optimization to consider is using bisection. If our program is deterministic (and is therefore reproducible), then instead of going line-by-line, a developer can (and usually will) try one point around the middle of the program, check the whole state, and then will see if the bug has already happened, or if it hasn’t happened yet. The process can then be repeated. In this case, we’ll have
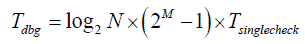
Note that we cannot easily combine our two optimizations because the first one is essentially incremental, which doesn’t fit the second one. In practice, usually a ‘hybrid’ method is used (first the developer tries bisection, and then, when the span of a potential bug is small enough, goes incrementally), but we feel that it won’t change the asymptotes of our findings.
Basic sanity checks
Now, when we have the model, we need to check how it corresponds to the real world. One can build a lot of internally non-contradictory theories, which become obviously invalid at the very first attempt to match them to the real world. We’ve already made enough assumptions to realize the need for sanity checks. We also realize that the list of our sanity checks is incomplete and that therefore it is perfectly possible that our model won’t stand further scrutiny.
The first sanity check is against intuitive observations, that the longer the program, and the more variables it has, the more difficult it is to debug. Our formulae seem to pass this check. The next sanity check is against another intuitive observation that debugging complexity grows non-linearly with the program size; as usually both N and M grow with the program size, so our formulae seem to pass this check too.
Sanity check – effects of decoupling on debugging complexity
Now we want to consider a more complicated case. Since the 70s, one of the biggest improvements in tackling program (and debugging) complexity has been the introduction of OO with hidden data, well-defined interfaces, and reduced coupling. In other words, we all know that coupling is bad (and we feel that no complexity model can be reasonably accurate without taking this into account); let’s see how our model deals with it. If we split M ‘absolutely tightly’ coupled variables into two bunches of uncoupled variables, each being M /2 in size, and each such group has only M /2× K p2p public member variables ( K p2p here stands for ‘public-to-private ratio’, and 0 <= K p2p <= 1), then our initial formula [1] (without optimizations) will become
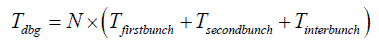
where both T firstbunch and T secondbunch are equal to
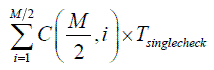
and
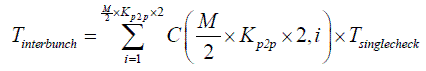
After some calculations, we’ll get that
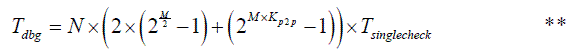
It means that if we have 10 variables, then splitting them into 2 bunches of 5 variables each, with only 2 public member variables exposed from each bunch (so K p2p =0.4), will reduce debugging time from approx. 2 10 × T singlecheck (according to *), to approx. (2 6 +2 4 )× T singlecheck (according to **). So yes, indeed our model shows that coupling is a bad thing for debugging complexity, and we can consider this sanity check to be passed too.
Conclusion
In this article, we have built a mathematical model of debugging complexity. This model is based on many assumptions, and is far from being perfect. Still, we hope that it can either serve as a basis for building more accurate models, or that it at least will cause discussions, leading to the development of better models in the field of debugging complexity.

References
[CAEPIA09] On the complexity of program debugging using constraints for modeling the program's syntax and semantics, Franz Wotawa, Jörg Weber, Mihai Nica, Rafael Ceballos, Proceedings of the Current topics in artificial intelligence, and 13th conference on Spanish association for artificial intelligence.
[CP07] Exploring different constraint-based modelings for program verification, Hélène Collavizza, Michel Rueher , Proceedings of the 13th international conference on Principles and practice of constraint programming.
[Loganberry04] David ‘Loganberry’, Frithaes! – an Introduction to Colloquial Lapine!, http://bitsnbobstones.watershipdown.org/lapine/overview.html
Acknowledgement
Cartoon by Sergey Gordeev from Gordeev Animation Graphics, Prague.

